её°з„Ўд»®иӘ¬гҒ®жңүж„ҸжҖ§жӨңе®ҡ гҒ«гҒҠгҒ„гҒҰгҖҒp еҖӨp -value[ жіЁ 1] её°з„Ўд»®иӘ¬ гҒҢжӯЈгҒ—гҒ„гҒЁгҒ„гҒҶд»®е®ҡгҒ®дёӢгҒ§гҖҒе®ҹйҡӣгҒ«иҰіеҜҹгҒ•гӮҢгҒҹзөҗжһң гҒЁе°‘гҒӘгҒҸгҒЁгӮӮеҗҢгҒҳгҒҸгӮүгҒ„жҘөз«ҜгҒӘжӨңе®ҡзөҗжһңгӮ’еҫ—гӮӢзўәзҺҮгҒ§гҒӮгӮӢ[ 2] [ 3] p еҖӨгҒҢйқһеёёгҒ«е°ҸгҒ•гҒ„гҒ“гҒЁгҒҜгҖҒгҒқгҒ®гӮҲгҒҶгҒӘжҘөз«ҜгҒӘиҰіжё¬зөҗжһң гҒҜеё°з„Ўд»®иӘ¬гҒ®дёӢгҒ§гҒҜжҘөгӮҒгҒҰиө·гҒ“гӮҠгҒ«гҒҸгҒ„гҒ“гҒЁгӮ’ж„Ҹе‘ігҒҷгӮӢгҖӮеӨҡгҒҸгҒ®е®ҡйҮҸзҡ„гҒӘеҲҶйҮҺгҒ®еӯҰиЎ“еҮәзүҲзү© гҒ§гҒҜгҖҒзөұиЁҲзҡ„жӨңе®ҡгҒ® p еҖӨгҒҢдёҖиҲ¬зҡ„гҒ«е ұе‘ҠгҒ•гӮҢгҒҰгҒ„гӮӢгҒ«гӮӮгҒӢгҒӢгӮҸгӮүгҒҡгҖҒp еҖӨгҒ®иӘӨгҒЈгҒҹи§ЈйҮҲгӮ„ p еҖӨгҒ®иӘӨз”ЁпјҲиӢұиӘһзүҲ пјү гғЎгӮҝгӮөгӮӨгӮЁгғігӮ№ пјҲиӢұиӘһзүҲ пјү [ 4] [ 5] гӮўгғЎгғӘгӮ«зөұиЁҲеӯҰдјҡ пјҲASAпјүгҒҜжӯЈејҸгҒӘеЈ°жҳҺгӮ’зҷәиЎЁгҒ—гҖҒгҖҢp еҖӨгҒҜгҖҒз ”з©¶еҜҫиұЎгҒЁгҒӘгҒЈгҒҹд»®иӘ¬гҒҢжӯЈгҒ—гҒ„зўәзҺҮгӮ„гҖҒгғҮгғјгӮҝгҒҢеҒ¶з„¶гҒ гҒ‘гҒ§з”ҹгҒҳгҒҹзўәзҺҮгӮ’жё¬е®ҡгҒҷгӮӢгӮӮгҒ®гҒ§гҒҜгҒӘгҒ„гҖҚгҒЁиҝ°гҒ№гҖҒгҖҢp еҖӨгҖҒгҒҷгҒӘгӮҸгҒЎзөұиЁҲзҡ„жңүж„ҸжҖ§ гҒҜгҖҒеҠ№жһңгҒ®еӨ§гҒҚгҒ•гӮ„зөҗжһңгҒ®йҮҚиҰҒжҖ§гӮ’жё¬е®ҡгҒҷгӮӢгӮӮгҒ®гҒ§гҒҜгҒӘгҒ„гҖҚгҒҫгҒҹгҒҜгҖҢгғўгғҮгғ«гӮ„д»®иӘ¬гҒ«й–ўгҒҷгӮӢиЁјжӢ гҖҚгҒ§гҒҜгҒӘгҒ„гҒЁгҒ—гҒҹ[ 6] p еҖӨгҒҠгӮҲгҒіжңүж„ҸжҖ§жӨңе®ҡгҒҜгҖҒйҒ©еҲҮгҒ«з”ЁгҒ„гӮүгӮҢи§ЈйҮҲгҒ•гӮҢгҒҹе ҙеҗҲгҖҒгғҮгғјгӮҝгҒӢгӮүе°ҺгҒҚеҮәгҒ•гӮҢгӮӢзөҗи«–гҒ®еҺіеҜҶжҖ§гӮ’й«ҳгӮҒгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгӮӢгҖҚгҒЁзөҗи«–гҒҘгҒ‘гҒҰгҒ„гӮӢ[ 7]
зөұиЁҲеӯҰгҒ§гҒҜгҖҒгҒӮгӮӢз ”з©¶гҒ«гҒҠгҒ‘гӮӢиҰіжё¬гғҮгғјгӮҝ
X
{\displaystyle X}
зўәзҺҮеҲҶеёғ гҒ«й–ўгҒҷгӮӢгҒӮгӮүгӮҶгӮӢжҺЁжё¬гӮ’зөұиЁҲзҡ„д»®иӘ¬ пјҲstatistical hypothesisпјүгҒЁе‘јгҒ¶гҖӮзөұиЁҲзҡ„жӨңе®ҡгҒ®зӣ®зҡ„гҒҢгҖҒдёҖгҒӨгҒ гҒ‘иҝ°гҒ№гҒҹд»®иӘ¬гҒҢеҰҘеҪ“гҒ§гҒӮгӮӢгҒӢгҒ©гҒҶгҒӢгӮ’жӨңиЁјгҒҷгӮӢгҒ“гҒЁгҒ§гҒӮгҒЈгҒҰгҖҒеҲҘгҒ®зү№е®ҡгҒ®д»®иӘ¬гӮ’жӨңиЁјгҒҷгӮӢгҒ“гҒЁгҒ§гҒҜгҒӘгҒ„е ҙеҗҲгҖҒгҒқгҒ®гӮҲгҒҶгҒӘжӨңе®ҡгҒҜеё°з„Ўд»®иӘ¬жӨңе®ҡ пјҲnull hypothesis testгҖҒжЈ„еҚҙжӨңе®ҡгҒЁгӮӮпјүгҒЁе‘јгҒ°гӮҢгӮӢгҖӮ
е®ҡзҫ©дёҠгҖҒзөұиЁҲзҡ„д»®иӘ¬гҒЁгҒҜгҖҒеҲҶеёғгҒ®дҪ•гӮүгҒӢгҒ®зү№еҫҙгӮ’жҢҮгҒҷгӮӮгҒ®гҒ§гҒӮгӮҠгҖҒеё°з„Ўд»®иӘ¬ гҒЁгҒҜгҖҒгҒқгҒ®зү№еҫҙгҒҢеӯҳеңЁгҒ—гҒӘгҒ„гҒЁгҒ„гҒҶгғҮгғ•гӮ©гғ«гғҲд»®иӘ¬гӮ’жҢҮгҒҷгҖӮйҖҡеёёгҖҒеё°з„Ўд»®иӘ¬гҒҜгҖҒй–ўеҝғгҒ®гҒӮгӮӢжҜҚйӣҶеӣЈ гҒ®дҪ•гӮүгҒӢгҒ®гғ‘гғ©гғЎгғјгӮҝпјҲзӣёй–ўгӮ„е№іеқҮеҖӨгҒ®е·®гҒӘгҒ©пјүгҒҢ 0 гҒ§гҒӮгӮӢгҒЁгҒ„гҒҶд»®иӘ¬гҒ§гҒӮгӮӢгҖӮгҒқгҒ®д»®иӘ¬гҒҜгҖҒ
X
{\displaystyle X}
X
{\displaystyle X}
T
{\displaystyle T}
е‘ЁиҫәзўәзҺҮеҲҶеёғ гҒҜз ”з©¶гҒ«гҒҠгҒ‘гӮӢдё»гҒӘй–ўеҝғдәӢгҒЁеҜҶжҺҘгҒ«й–ўйҖЈгҒ—гҒҰгҒ„гӮӢгҖӮ
p еҖӨгҒҜгҖҒйҒёе®ҡгҒ—гҒҹзөұиЁҲйҮҸ
T
{\displaystyle T}
зөұиЁҲзҡ„жңүж„ҸжҖ§ гӮ’е®ҡйҮҸеҢ–гҒҷгӮӢгҒҹгӮҒгҒ«гҖҒеё°з„Ўд»®иӘ¬жӨңе®ҡгҒ®ж–Үи„ҲгҒ§дҪҝз”ЁгҒ•гӮҢгӮӢ[ жіЁ 2] p еҖӨгҒҢдҪҺгҒ„гҒ»гҒ©гҖҒеё°з„Ўд»®иӘ¬гҒҢжӯЈгҒ—гҒ„е ҙеҗҲгҒ«гҖҒгҒқгҒ®зөҗжһңгӮ’еҫ—гӮӢзўәзҺҮгҒҢдҪҺгҒ„гҒ“гҒЁгӮ’ж„Ҹе‘ігҒҷгӮӢгҖӮеё°з„Ўд»®иӘ¬гӮ’жЈ„еҚҙгҒ§гҒҚгӮӢе ҙеҗҲгҖҒгҒқгҒ®зөҗжһңгҒҜзөұиЁҲзҡ„гҒ«жңүж„ҸпјҲstatistically significantпјүгҒ§гҒӮгӮӢгҒЁиҰӢгҒӘгҒ•гӮҢгӮӢгҖӮд»–гҒ®жқЎд»¶гҒҢгҒҷгҒ№гҒҰеҗҢгҒҳгҒ§гҒӮгӮҢгҒ°гҖҒp еҖӨгҒҢе°ҸгҒ•гҒ„гҒ»гҒ©гҖҒеё°з„Ўд»®иӘ¬гӮ’еҗҰе®ҡгҒҷгӮӢгӮҲгӮҠеј·гҒ„иЁјжӢ гҒЁиҰӢгҒӘгҒ•гӮҢгӮӢгҖӮ
еӨ§гҒҫгҒӢгҒ«иЁҖгҒҲгҒ°гҖҒеё°з„Ўд»®иӘ¬гҒ®жЈ„еҚҙгҒҜгҖҒгҒқгӮҢгҒЁгҒҜеҸҚеҜҫгҒ®еҚҒеҲҶгҒӘиЁјжӢ гҒҢгҒӮгӮӢгҒ“гҒЁгӮ’ж„Ҹе‘ігҒҷгӮӢгҖӮ
дёҖдҫӢгҒЁгҒ—гҒҰгҖҒгҖҢгҒӮгӮӢиҰҒзҙ„зөұиЁҲйҮҸ
T
{\displaystyle T}
жЁҷжә–жӯЈиҰҸеҲҶеёғ
N
(
0
,
1
)
{\displaystyle {\mathcal {N}}(0,1)}
T
{\displaystyle T}
T
{\displaystyle T}
еҲҶж•Ј гҒҢ 1 гҒ§гҒҜгҒӘгҒ„гҖҒ(3)
T
{\displaystyle T}
еҜҫз«Ӣд»®иӘ¬ гҒ«еҜҫгҒ—гҒҷгӮӢж„ҹеәҰгҒҢгҒқгӮҢгҒһгӮҢз•°гҒӘгӮӢгҖӮгҒ—гҒӢгҒ—гҖҒ3гҒӨгҒ®еҜҫз«Ӣд»®иӘ¬гҒҷгҒ№гҒҰгҒҢеё°з„Ўд»®иӘ¬гӮ’жЈ„еҚҙгҒ§гҒҚгҖҒгҒқгҒ®еҲҶеёғгҒҢжӯЈиҰҸеҲҶеёғгҒ§еҲҶж•ЈгҒҢ 1гҒ§гҒӮгӮӢгҒЁеҲҶгҒӢгҒЈгҒҰгҒ„гҒҹгҒЁгҒ—гҒҰгӮӮгҖҒеё°з„Ўд»®иӘ¬жӨңе®ҡгҒ§гҒҜгҖҒе№іеқҮгҒҢйқһ 0 гҒ®еҖӨгҒ®гҒҶгҒЎгҖҒгҒ©гӮҢгҒҢжңҖгӮӮеҰҘеҪ“гҒ§гҒӮгӮӢгҒӢгҒҜгӮҸгҒӢгӮүгҒӘгҒ„гҖӮеҗҢгҒҳзўәзҺҮеҲҶеёғгҒ«еҫ“гҒҶзӢ¬з«ӢгҒ—гҒҹиҰіжё¬еҖӨгҒҢеӨҡгҒ‘гӮҢгҒ°еӨҡгҒ„гҒ»гҒ©гҖҒгҒқгҒ®жӨңе®ҡгҒ®зІҫеәҰгҒҜеҗ‘дёҠгҒ—гҖҒе№іеқҮеҖӨгӮ’жӯЈзўәгҒ«жұәе®ҡгҒ—гҖҒгҒқгӮҢгҒҢ 0 гҒ§гҒӘгҒ„гҒ“гҒЁгӮ’зӨәгҒҷзІҫеәҰгӮӮй«ҳгҒҸгҒӘгӮӢгҖӮгҒқгӮҢгҒ гҒ‘гҒ§гҒӘгҒҸгҖҒгҒ“гҒ®еҒҸе·®гҒ®зҸҫе®ҹдё–з•ҢгҒӮгӮӢгҒ„гҒҜ科еӯҰзҡ„гҒӘеҰҘеҪ“жҖ§гҒ®и©•дҫЎгҒ«дёҺгҒҲгӮүгӮҢгӮӢйҮҚгҒҝгӮӮй«ҳгҒҫгӮӢгҖӮ
p еҖӨгҒҜгҖҒеё°з„Ўд»®иӘ¬гҒ®дёӢгҒ§гҖҒе®ҹйҡӣгҒ®жӨңе®ҡзөұиЁҲйҮҸгҒЁе°‘гҒӘгҒҸгҒЁгӮӮеҗҢгҒҳгҒҸгӮүгҒ„жҘөз«ҜгҒӘжӨңе®ҡзөұиЁҲйҮҸгҒҢеҫ—гӮүгӮҢгӮӢзўәзҺҮгҒ§гҒӮгӮӢгҖӮжңӘзҹҘгҒ®еҲҶеёғ
T
{\displaystyle T}
t
{\displaystyle t}
p еҖӨ
p
{\displaystyle p}
H
0
{\displaystyle H_{0}}
t
{\displaystyle t}
дәӢеүҚзўәзҺҮ гҒ§гҒӮгӮӢгҖӮгҒҷгҒӘгӮҸгҒЎгҖҒ
p
=
Pr
(
T
≥ вүҘ -->
t
∣ вҲЈ -->
H
0
)
{\displaystyle p=\Pr(T\geq t\mid H_{0})}
p
=
Pr
(
T
≤ вүӨ -->
t
∣ вҲЈ -->
H
0
)
{\displaystyle p=\Pr(T\leq t\mid H_{0})}
p
=
2
min
{
Pr
(
T
≥ вүҘ -->
t
∣ вҲЈ -->
H
0
)
,
Pr
(
T
≤ вүӨ -->
t
∣ вҲЈ -->
H
0
)
}
{\displaystyle p=2\min\{\Pr(T\geq t\mid H_{0}),\Pr(T\leq t\mid H_{0})\}}
T
{\displaystyle T}
p
=
Pr
(
|
T
|
≥ вүҘ -->
|
t
|
∣ вҲЈ -->
H
0
)
{\displaystyle p=\Pr(|T|\geq |t|\mid H_{0})}
е®ҹи·өзҡ„гҒӘзөұиЁҲеӯҰиҖ…гҒҢгӮӮгҒЈгҒЁгӮӮйҒҝгҒ‘гӮӢгҒ№гҒҚгҒЁиҖғгҒҲгӮӢйҒҺиӘӨпјҲдё»иҰізҡ„гҒӘгӮӮгҒ®пјүгҒҜ
第дёҖзЁ®гҒ®йҒҺиӘӨ гҒ§гҒӮгӮӢгҖӮж•°еӯҰзҗҶи«–гҒ®з¬¬дёҖгҒ®иҰҒ件гҒҜгҖҒ第дёҖзЁ®гҒ®йҒҺиӘӨгӮ’зҠҜгҒҷзўәзҺҮгҒҢгҖҒгҒӮгӮүгҒӢгҒҳгӮҒе®ҡгӮҒгӮүгӮҢгҒҹж•° ОұпјҲгҒҹгҒЁгҒҲгҒ° Оұ = 0.05 гӮ„ 0.01 гҒӘгҒ©пјүгҒ«зӯүгҒ—гҒ„пјҲгҒҫгҒҹгҒҜгҒ»гҒјзӯүгҒ—гҒ„гҖҒгҒҫгҒҹгҒҜи¶…гҒҲгҒӘгҒ„пјүгҒ“гҒЁгӮ’дҝқиЁјгҒҷгӮӢжӨңе®ҡеҹәжә–гӮ’е°ҺгҒҚеҮәгҒҷгҒ“гҒЁгҒ§гҒӮгӮӢгҖӮгҒ“гҒ®ж•°еӯ—гӮ’жңүж„Ҹж°ҙжә–гҒЁе‘јгҒ¶гҖӮ
—
Jerzy NeymanгҖҒ"The Emergence of Mathematical Statistics"[ 8] жңүж„Ҹе·®жӨңе®ҡгҒ§гҒҜгҖҒp еҖӨгҒҢдәӢеүҚгҒ«иЁӯе®ҡгҒ—гҒҹй–ҫеҖӨ
α Оұ -->
{\displaystyle \alpha }
H
0
{\displaystyle H_{0}}
α Оұ -->
{\displaystyle \alpha }
α Оұ -->
{\displaystyle \alpha }
жңүж„Ҹж°ҙжә– пјҲsignificance levelпјүгҒЁе‘јгҒ°гӮҢгӮӢгҖӮ
α Оұ -->
{\displaystyle \alpha }
α Оұ -->
{\displaystyle \alpha }
α Оұ -->
{\displaystyle \alpha }
[ 9]
зӢ¬з«ӢгҒ—гҒҹгғҮгғјгӮҝгӮ»гғғгғҲгҒ«еҹәгҒҘгҒҸз•°гҒӘгӮӢ p еҖӨгҒ©гҒҶгҒ—гҒҜгҖҒгҒҹгҒЁгҒҲгҒ°гғ•гӮЈгғғгӮ·гғЈгғјгҒ®зөҗеҗҲзўәзҺҮжӨңе®ҡ пјҲиӢұиӘһзүҲ пјү
p еҖӨгҒҜгҖҒйҒёе®ҡгҒ•гӮҢгҒҹжӨңе®ҡзөұиЁҲйҮҸ
T
{\displaystyle T}
зўәзҺҮеӨүж•° гҒ§гҒӮгӮӢгҖӮеё°з„Ўд»®иӘ¬гҒҢ
T
{\displaystyle T}
H
0
:
θ Оё -->
=
θ Оё -->
0
,
{\displaystyle H_{0}:\theta =\theta _{0},}
θ Оё -->
{\displaystyle \theta }
p еҖӨгҒҜ 0 гҒӢгӮү 1 гҒ®й–“гҒ®дёҖж§ҳеҲҶеёғ гҒЁгҒӘгӮӢгҖӮ
H
0
{\displaystyle H_{0}}
p еҖӨгҒҜеӣәе®ҡеҖӨгҒ§гҒҜгҒӘгҒ„гҖӮеҗҢгҒҳжӨңе®ҡгӮ’ж–°гҒ—гҒ„гғҮгғјгӮҝгҒ§зӢ¬з«ӢгҒ—гҒҰз№°гӮҠиҝ”гҒ—гҒҹе ҙеҗҲгҖҒйҖҡеёёгҖҒеҗ„еҸҚеҫ©гҒ§з•°гҒӘгӮӢ p еҖӨгҒҢеҫ—гӮүгӮҢгӮӢгҖӮ
йҖҡеёёгҖҒгҒӮгӮӢд»®иӘ¬гҒ«й–ўйҖЈгҒ—гҒҰиҰіеҜҹгҒ•гӮҢгӮӢ p еҖӨгҒҜ 1гҒӨгҒ гҒ‘гҒ§гҒӮгӮӢгҒҹгӮҒгҖҒp еҖӨгҒҜжңүж„Ҹе·®жӨңе®ҡгҒ«гӮҲгҒЈгҒҰи§ЈйҮҲгҒ•гӮҢгҖҒp еҖӨгҒ®еҲҶеёғгӮ’жҺЁе®ҡгҒҷгӮӢи©ҰгҒҝгҒҜгҒӘгҒ•гӮҢгҒӘгҒ„гҖӮp еҖӨгҒ®йӣҶеҗҲгҒҢеҲ©з”ЁеҸҜиғҪгҒӘе ҙеҗҲпјҲдҫӢпјҡеҗҢгҒҳдё»йЎҢгҒ«й–ўгҒҷгӮӢдёҖйҖЈгҒ®з ”究гҒ®жӨңиЁјпјүгҖҒp еҖӨгҒ®еҲҶеёғгҒҜ p жӣІз·ҡпјҲp -curveпјүгҒЁе‘јгҒ°гӮҢгӮӢгҒ“гҒЁгҒҢгҒӮгӮӢ[ 10] p жӣІз·ҡгҒҜгҖҒеҮәзүҲгғҗгӮӨгӮўгӮ№ гӮ„ pеҖӨгғҸгғғгӮӯгғігӮ° пјҲиӢұиӘһзүҲ пјү [ 10] [ 11]
гғ‘гғ©гғЎгғҲгғӘгғғгӮҜд»®иӘ¬жӨңе®ҡе•ҸйЎҢгҒ§гҒҜгҖҒеҚҳзҙ”д»®иӘ¬гҒҫгҒҹгҒҜзӮ№д»®иӘ¬гҒЁгҒҜгҖҒгғ‘гғ©гғЎгғјгӮҝгҒ®еҖӨгҒҢеҚҳдёҖгҒ®ж•°еҖӨгҒ§гҒӮгӮӢгҒЁжғіе®ҡгҒҷгӮӢд»®иӘ¬гҒ§гҒӮгӮӢгҖӮгҒ“гӮҢгҒ«еҜҫгҒ—гҖҒиӨҮеҗҲд»®иӘ¬пјҲcomposite hypothesis (en:иӢұиӘһзүҲ ) пјүгҒ§гҒҜгҖҒгғ‘гғ©гғЎгғјгӮҝгҒҜдёҖйҖЈгҒ®ж•°еҖӨгҒ«гӮҲгҒЈгҒҰиЎЁгҒ•гӮҢгӮӢгҖӮеё°з„Ўд»®иӘ¬гҒҢиӨҮеҗҲд»®иӘ¬гҒ§гҒӮгӮӢе ҙеҗҲпјҲгҒҫгҒҹгҒҜзөұиЁҲйҮҸгҒ®еҲҶеёғгҒҢйӣўж•Јзҡ„гҒ§гҒӮгӮӢе ҙеҗҲпјүгҖҒеё°з„Ўд»®иӘ¬гҒҢзңҹгҒ§гҒӮгӮҢгҒ°гҖҒ0 гҒӢгӮү 1 гҒҫгҒ§гҒ®д»»ж„ҸгҒ®ж•°еҖӨд»ҘдёӢгҒЁгҒӘгӮӢ p еҖӨгӮ’еҫ—гӮӢзўәзҺҮгҒҜгҖҒгҒқгӮҢгӮүгҒ®ж•°гӮ’дҫқ然гҒЁгҒ—гҒҰдёӢеӣһгӮӢ[иЁіиӘһз–‘е•ҸзӮ№ гҖӮиЁҖгҒ„жҸӣгҒҲгӮҢгҒ°гҖҒеё°з„Ўд»®иӘ¬гҒҢзңҹгҒ§гҒӮгӮӢе ҙеҗҲгҖҒйқһеёёгҒ«е°ҸгҒ•гҒӘ p еҖӨгҒҜжҜ”ијғзҡ„зҷәз”ҹгҒ—гҒ«гҒҸгҒҸгҖҒгҒҫгҒҹ p еҖӨгҒҢ
α Оұ -->
{\displaystyle \alpha }
α Оұ -->
{\displaystyle \alpha }
[ 12] [ 13]
гҒҹгҒЁгҒҲгҒ°гҖҒгҒӮгӮӢеҲҶеёғгҒҢжӯЈиҰҸеҲҶеёғгҒ§е№іеқҮеҖӨ 0 д»ҘдёӢгҒ§гҒӮгӮӢгҒЁгҒ„гҒҶеё°з„Ўд»®иӘ¬гӮ’гҖҒе№іеқҮеҖӨгҒҢ 0 гӮҲгӮҠеӨ§гҒҚгҒ„гҒЁгҒ„гҒҶеҜҫз«Ӣд»®иӘ¬пјҲ
H
0
:
μ Ој -->
≤ вүӨ -->
0
{\displaystyle H_{0}:\mu \leq 0}
Z жӨңе®ҡгҒ«еұһгҒҷгӮӢ Z зөұиЁҲйҮҸZ жӨңе®ҡзөұиЁҲйҮҸгҒҜз•°гҒӘгӮӢзўәзҺҮеҲҶеёғгӮ’жҢҒгҒӨгҖӮгҒ“гҒ®гӮҲгҒҶгҒӘзҠ¶жіҒгҒ§гҒҜгҖҒp еҖӨгҒҜжңҖгӮӮдёҚеҲ©гҒӘеё°з„Ўд»®иӘ¬гҒ®зҠ¶жіҒпјҲйҖҡеёёгҒҜеё°з„Ўд»®иӘ¬гҒЁеҜҫз«Ӣд»®иӘ¬гҒ®еўғз•Ңз·ҡдёҠгҒ«гҒӮгӮӢпјүгҒ«еҹәгҒҘгҒ„гҒҰе®ҡзҫ©гҒ•гӮҢгӮӢгҖӮгҒ“гҒ®е®ҡзҫ©гҒ«гӮҲгӮҠгҖҒp еҖӨгҒҠгӮҲгҒі Оұж°ҙжә–гҒҢзӣёдә’гҒ«иЈңе®ҢгҒ—гҒӮгҒҶгҒ“гҒЁгҒҢдҝқиЁјгҒ•гӮҢгӮӢгҖӮ
α Оұ -->
=
0.05
{\displaystyle \alpha =0.05}
p еҖӨгҒҢ 0.05 гӮ’дёӢеӣһгӮӢе ҙеҗҲгҒ«гҒ®гҒҝеё°з„Ўд»®иӘ¬гҒҢжЈ„еҚҙгҒ•гӮҢгӮӢгҒ“гҒЁгӮ’ж„Ҹе‘ігҒ—гҖҒгҒқгҒ®д»®иӘ¬жӨңе®ҡгҒ®з¬¬дёҖзЁ®йҒҺиӘӨзҺҮ гҒҜе®ҹйҡӣгҒ« 0.05 гҒҢдёҠйҷҗгҒЁгҒӘгӮӢгҖӮ
p еҖӨгҒҜгҖҒзөұиЁҲзҡ„д»®иӘ¬жӨңе®ҡ гҖҒзү№гҒ«её°з„Ўд»®иӘ¬гҒ®жңүж„Ҹе·®жӨңе®ҡгҒ«гҒҠгҒ„гҒҰеәғгҒҸз”ЁгҒ„гӮүгӮҢгҒҰгҒ„гӮӢгҖӮгҒ“гҒ®ж–№жі•гҒ§гҒҜгҖҒз ”з©¶гӮ’иЎҢгҒҶеүҚгҒ«гҖҒгҒҫгҒҡгғўгғҮгғ«пјҲеё°з„Ўд»®иӘ¬ пјүгҒЁжңүж„Ҹж°ҙжә– ОұпјҲдёҖиҲ¬зҡ„гҒ«0.05пјүгҒҢйҒёжҠһгҒ•гӮҢгӮӢгҖӮгғҮгғјгӮҝгӮ’еҲҶжһҗгҒ—гҒҹеҫҢгҖҒp еҖӨгҒҢ ОұгӮҲгӮҠе°ҸгҒ•гҒ„е ҙеҗҲгҖҒиҰіеҜҹгҒ•гӮҢгҒҹгғҮгғјгӮҝгҒҢеё°з„Ўд»®иӘ¬гҒЁеҚҒеҲҶгҒ«зҹӣзӣҫгҒ—гҒҰгҒ„гӮӢгҒЁиҰӢгҒӘгҒ•гӮҢгӮӢгҒҹгӮҒгҖҒеё°з„Ўд»®иӘ¬гҒҜжЈ„еҚҙгҒ•гӮҢгӮӢгҖӮгҒ—гҒӢгҒ—гҖҒгҒ“гӮҢгҒҜеё°з„Ўд»®иӘ¬гҒҢиӘӨгӮҠгҒ§гҒӮгӮӢгҒЁгҒ„гҒҶгҒ“гҒЁгӮ’иЁјжҳҺгҒҷгӮӢгӮӮгҒ®гҒ§гҒҜгҒӘгҒ„гҖӮp еҖӨгҒҜгҒқгӮҢиҮӘдҪ“гҒ§д»®иӘ¬гҒ®зўәгҒӢгӮүгҒ—гҒ•гӮ’зӨәгҒҷгӮӮгҒ®гҒ§гҒҜгҒӘгҒ„гҖӮгӮҖгҒ—гӮҚгҖҒp еҖӨгҒҜгҖҒеё°з„Ўд»®иӘ¬гӮ’жЈ„еҚҙгҒҷгҒ№гҒҚгҒӢгҒ©гҒҶгҒӢгӮ’еҲӨж–ӯгҒҷгӮӢйҒ“е…·гҒ§гҒӮгӮӢ[ 14]
гӮўгғЎгғӘгӮ«зөұиЁҲеӯҰдјҡпјҲASAпјүгҒ«гӮҲгӮӢгҒЁгҖҒp еҖӨгҒҜиӘӨз”ЁгҒ•гӮҢгҖҒиӘӨгҒЈгҒҰи§ЈйҮҲгҒ•гӮҢгӮӢгҒ“гҒЁгҒҢеӨҡгҒ„гҒ“гҒЁгҒҢеәғгҒҸиӘҚгӮҒгӮүгӮҢгҒҰгҒ„гӮӢ[ 3] p еҖӨгҒҢ 0.05 жңӘжәҖгҒ§гҒӮгӮҢгҒ°еҜҫз«Ӣд»®иӘ¬гӮ’еҸ—гҒ‘е…ҘгӮҢгӮӢгҒЁгҒ„гҒҶж…ЈиЎҢгҒ§гҒӮгӮӢгҖӮp еҖӨгҒҜгҖҒгғҮгғјгӮҝгҒҢзү№е®ҡгҒ®зөұиЁҲгғўгғҮгғ«гҒЁгҒ©гҒ®зЁӢеәҰзҹӣзӣҫгҒ—гҒҰгҒ„гӮӢгҒӢгӮ’и©•дҫЎгҒҷгӮӢгҒЁгҒҚгҒ«жңүз”ЁгҒ§гҒӮгӮӢгҒҢгҖҒгҖҢз ”з©¶гҒ®иЁҲз”»гҖҒжё¬е®ҡгҒ®иіӘгҖҒз ”з©¶еҜҫиұЎгҒ®зҸҫиұЎгҒ«й–ўгҒҷгӮӢеӨ–зҡ„иЁјжӢ гҖҒгғҮгғјгӮҝеҲҶжһҗгҒ®еҹәзӨҺгҒЁгҒӘгӮӢд»®е®ҡгҒ®еҰҘеҪ“жҖ§гҖҚгҒӘгҒ©гҒ®зҠ¶жіҒзҡ„иҰҒеӣ гӮӮиҖғж…®гҒ—гҒӘгҒ‘гӮҢгҒ°гҒӘгӮүгҒӘгҒ„[ 3] p еҖӨгҒҢеё°з„Ўд»®иӘ¬гҒҢзңҹгҒ§гҒӮгӮӢзўәзҺҮгҒЁиӘӨи§ЈгҒ•гӮҢгӮӢгҒ“гҒЁгҒҢеӨҡгҒ„гҒ“гҒЁгҒ§гҒӮгӮӢ[ 3] [ 15]
дёҖйғЁгҒ®зөұиЁҲеӯҰиҖ…гҒҜгҖҒp еҖӨгӮ’ж”ҫжЈ„гҒ—[ 3] дҝЎй јеҢәй–“ [ 16] [ 17] е°ӨеәҰжҜ” [ 18] [ 19] гғҷгӮӨгӮәеӣ еӯҗ [ 20] [ 21] [ 22] [ 23] [ 24] p еҖӨгӮ’её°з„Ўд»®иӘ¬гҒ«еҜҫгҒҷгӮӢиЁјжӢ гҒ®еј·гҒ•гӮ’зӨәгҒҷйҖЈз¶ҡзҡ„гҒӘжҢҮжЁҷгҒЁгҒ—гҒҰи§ЈйҮҲгҒҷгҒ№гҒҚгҒ гҒЁгҒ„гҒҶж„ҸиҰӢгӮӮгҒӮгӮӢ[ 25] [ 26] p еҖӨгҒЁгҒЁгӮӮгҒ«е ұе‘ҠгҒҷгӮӢгҒЁгҒ„гҒҶжҸҗжЎҲгӮӮгҒӮгҒЈгҒҹ[ 27]
гҒқгҒҶгҒЁгҒҜгҒ„гҒҲгҖҒ2019е№ҙгҒ«ASAгҒ®гӮҝгӮ№гӮҜгғ•гӮ©гғјгӮ№гҒҢжӢӣйӣҶгҒ•гӮҢгҖҒ科еӯҰзҡ„з ”з©¶гҒ«гҒҠгҒ‘гӮӢзөұиЁҲзҡ„жүӢжі•гҒ®дҪҝз”ЁгҖҒзү№гҒ«д»®иӘ¬жӨңе®ҡгҒЁ p еҖӨгҖҒгҒҠгӮҲгҒіеҶҚзҸҫеҸҜиғҪжҖ§гҒЁгҒ®й–ўйҖЈжҖ§гҒ«гҒӨгҒ„гҒҰжӨңиЁҺгҒ•гӮҢгҒҹ[ 7] p еҖӨгӮ’гҒӮгҒ’гҒҰгҒ„гӮӢгҖӮгҒҫгҒҹгҖҒp еҖӨгҒҜзү№е®ҡгҒ®еҖӨгҒ«гҒӨгҒ„гҒҰжӨңиЁҺгҒҷгӮӢе ҙеҗҲгҒ гҒ‘гҒ§гҒӘгҒҸгҖҒгҒӮгӮӢй–ҫеҖӨгҒЁжҜ”ијғгҒҷгӮӢе ҙеҗҲгҒ«гӮӮжңүз”ЁгҒӘжғ…е ұгӮ’жҸҗдҫӣгҒ§гҒҚгӮӢгҒ“гҒЁгӮ’еј·иӘҝгҒ—гҒҰгҒ„гӮӢгҖӮдёҖиҲ¬зҡ„гҒ«гҖҢp еҖӨгҒҠгӮҲгҒіжңүж„Ҹе·®жӨңе®ҡгҒҜгҖҒйҒ©еҲҮгҒ«з”ЁгҒ„гӮүгӮҢи§ЈйҮҲгҒ•гӮҢгҒҹе ҙеҗҲгҖҒгғҮгғјгӮҝгҒӢгӮүе°ҺгҒҚеҮәгҒ•гӮҢгӮӢзөҗи«–гҒ®еҺіеҜҶжҖ§гӮ’й«ҳгӮҒгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгӮӢгҖҚгҒЁеј·иӘҝгҒ—гҒҰгҒ„гӮӢгҖӮ
йҖҡеёёгҖҒ
T
{\displaystyle T}
жӨңе®ҡзөұиЁҲйҮҸ гҒ§гҒӮгӮӢгҖӮжӨңе®ҡзөұиЁҲйҮҸгҒҜгҖҒиҰіжё¬гҒ•гӮҢгҒҹгҒҷгҒ№гҒҰгҒ®еҖӨгҒ«гӮҲгӮӢгӮ№гӮ«гғ©гғј й–ўж•°гҒ®еҮәеҠӣгҒ§гҒӮгӮӢгҖӮгҒ“гҒ®зөұиЁҲйҮҸгҒҜгҖҒt зөұиЁҲйҮҸпјҲиӢұиӘһзүҲ пјү F зөұиЁҲйҮҸ
гғҮгғјгӮҝгҒҢжӯЈиҰҸеҲҶеёғгҒӢгӮүгҒ®з„ЎдҪңзӮәжҠҪеҮәгӮөгғігғ—гғ«гҒ§гҒӮгӮӢгҒЁд»®е®ҡгҒ•гӮҢгӮӢйҮҚиҰҒгҒӘгӮұгғјгӮ№гҒ§гҒҜгҖҒжӨңе®ҡзөұиЁҲйҮҸгҒ®зү№жҖ§гҒЁгҒқгҒ®еҲҶеёғгҒ«й–ўгҒҷгӮӢд»®иӘ¬гҒ«еҝңгҒҳгҒҰгҖҒз•°гҒӘгӮӢеё°з„Ўд»®иӘ¬жӨңе®ҡгҒҢй–ӢзҷәгҒ•гӮҢгҒҰгҒ„гӮӢгҖӮгҒқгҒ®гӮҲгҒҶгҒӘжӨңе®ҡгҒ«гҒҜгҖҒеҲҶж•ЈгҒҢж—ўзҹҘгҒ®жӯЈиҰҸеҲҶеёғ гҒ®е№іеқҮгҒ«й–ўгҒҷгӮӢд»®иӘ¬гҒ«еҜҫгҒҷгӮӢ z жӨңе®ҡгӮ№гғҒгғҘгғјгғҮгғігғҲгҒ® t еҲҶеёғ гҒ«еҹәгҒҘгҒҸ t жӨңе®ҡF еҲҶеёғF жӨңе®ҡгғ”гӮўгӮҪгғігҒ®гӮ«гӮӨдәҢд№—жӨңе®ҡ (en:иӢұиӘһзүҲ ) гҒ®гӮҲгҒҶгҒӘгҖҒеӨ§иҰҸжЁЎгҒӘжЁҷжң¬гҒ«еҜҫгҒ—гҒҰдёӯеҝғжҘөйҷҗе®ҡзҗҶ гӮ’йҒ©з”ЁгҒ—гҒҰеҫ—гӮүгӮҢгӮӢйҒ©еҲҮгҒӘзөұиЁҲйҮҸгҒ®жӯЈиҰҸиҝ‘дјјгҒ«еҹәгҒҘгҒҸеё°з„Ўд»®иӘ¬еҲҶеёғгҒЁгҖҒгҒқгӮҢгҒ«еҹәгҒҘгҒҸжӨңе®ҡзөұиЁҲйҮҸгҒҢж§ӢзҜүгҒ•гӮҢгӮӢгҒ“гҒЁгҒҢгҒӮгӮӢгҖӮ
гҒ“гҒ®гӮҲгҒҶгҒ«гҖҒp еҖӨгӮ’з®—еҮәгҒҷгӮӢгҒ«гҒҜгҖҒеё°з„Ўд»®иӘ¬гҖҒжӨңе®ҡзөұиЁҲйҮҸпјҲзүҮеҒҙжӨңе®ҡгҒЁдёЎеҒҙжӨңе®ҡ пјҲиӢұиӘһзүҲ пјү зҙҜз©ҚеҲҶеёғй–ўж•° пјҲCDFпјүгҒ®з®—еҮәгҒҜгҒ—гҒ°гҒ—гҒ°йӣЈгҒ—гҒ„е•ҸйЎҢгҒЁгҒӘгӮӢгҖӮд»Ҡж—ҘгҒ§гҒҜгҖҒгҒ“гҒ®иЁҲз®—гҒҜзөұиЁҲгӮҪгғ•гғҲгӮҰгӮ§гӮўгӮ’дҪҝз”ЁгҒ—гҒҰиЎҢгӮҸгӮҢгҖҒеӨҡгҒҸгҒ®е ҙеҗҲгҖҒеҺіеҜҶгҒӘж•°ејҸгҒ§гҒҜгҒӘгҒҸж•°еҖӨи§Јжһҗ гҒҢдҪҝз”ЁгҒ•гӮҢгӮӢгҒҢгҖҒ20дё–зҙҖеүҚеҚҠгҒӢгӮүеҚҠгҒ°гҒ«гҒӢгҒ‘гҒҰгҒҜж•°еҖӨиЎЁгӮ’з”ЁгҒ„гҒҰгҒҠгӮҠгҖҒгҒ“гӮҢгӮүгҒ®йӣўж•ЈеҖӨгҒӢгӮү p еҖӨгӮ’еҶ…жҢҝгҒҫгҒҹгҒҜеӨ–жҢҝгҒ—гҒҰгҒ„гҒҹ[иҰҒеҮәе…ё гҖӮгғ•гӮЈгғғгӮ·гғЈгғјгҒҜгҖҒp еҖӨгҒ®иЎЁгӮ’дҪҝз”ЁгҒҷгӮӢд»ЈгӮҸгӮҠгҒ«гҖҒCDFгӮ’еҸҚи»ўгҒ•гҒӣгҖҒеӣәе®ҡ p еҖӨгҒ«еҜҫгҒҷгӮӢжӨңе®ҡзөұиЁҲйҮҸгҒ®еҖӨгҒ®дёҖиҰ§иЎЁгӮ’зҷәиЎЁгҒ—гҒҹгҖӮгҒ“гӮҢгҒҜгҖҒеҲҶдҪҚй–ўж•° пјҲиӢұиӘһзүҲ пјү
зөұиЁҲжӨңе®ҡгҒ®дёҖдҫӢгҒЁгҒ—гҒҰгҖҒгӮігӮӨгғіжҠ•гҒ’ гҒҢе…¬жӯЈ гҒӢпјҲиЎЁгҒЁиЈҸгҒҢеҮәгӮӢзўәзҺҮгҒҢзӯүгҒ—гҒ„пјүгҖҒдёҚжӯЈгҒ«еҒҸгҒЈгҒҰгҒ„гӮӢгҒӢпјҲгҒ©гҒЎгӮүгҒӢдёҖж–№гҒ®йқўгҒҢеҮәгӮӢзўәзҺҮгҒҢгӮҲгӮҠй«ҳгҒ„пјүгӮ’иӘҝгҒ№гӮӢе®ҹйЁ“гҒҢиЎҢгӮҸгӮҢгҒҹгҖӮ
е®ҹйЁ“гҒ§гҒҜгӮігӮӨгғігӮ’20еӣһжҠ•гҒ’гҖҒгҒҶгҒЎиЎЁгҒҢ14еӣһеҮәгҒҹгҖӮе…ЁгғҮгғјгӮҝ
X
{\displaystyle X}
T
{\displaystyle T}
е…¬жӯЈ гҒ§гҒӮгӮҠгҖҒгӮігӮӨгғіжҠ•гҒ’гҒҜдә’гҒ„гҒ«зӢ¬з«ӢгҒ§гҒӮгӮӢгҒЁгҒ„гҒҶгӮӮгҒ®гҒ§гҒӮгӮӢгҖӮгӮігӮӨгғігҒҢиЎЁгҒ«еҒҸгҒЈгҒҰгҒ„гӮӢеҸҜиғҪжҖ§гҒ«гҒӨгҒ„гҒҰе®ҹйҡӣгҒ«й–ўеҝғгҒҢгҒӮгӮӢгҒҹгӮҒгҖҒеҸіеҒҙжӨңе®ҡгӮ’иҖғж…®гҒҷгӮӢгҒ“гҒЁгҒ«гҒӘгӮӢгҖӮгҒ“гҒ®е ҙеҗҲгҖҒзөҗжһңгҒ® p еҖӨгҒҜгҖҒ20еӣһгҒ®е…¬жӯЈгҒӘгӮігӮӨгғіжҠ•гҒ’гҒ®гҒҶгҒЎе°‘гҒӘгҒҸгҒЁгӮӮ14еӣһгҒҢиЎЁгҒ«гҒӘгӮӢзўәзҺҮгҒ§гҒӮгӮӢгҖӮгҒ“гҒ®зўәзҺҮгҒҜгҖҒдәҢй …дҝӮж•° гҒӢгӮүж¬ЎгҒ®гӮҲгҒҶгҒ«иЁҲз®—гҒ§гҒҚгӮӢгҖӮ
Pr
(
14
heads
)
+
Pr
(
15
heads
)
+
⋯ вӢҜ -->
+
Pr
(
20
heads
)
=
1
2
20
[
(
20
14
)
+
(
20
15
)
+
⋯ вӢҜ -->
+
(
20
20
)
]
=
60
460
1
048
576
≈ вүҲ -->
0.058.
{\displaystyle {\begin{aligned}&\Pr(14{\text{ heads}})+\Pr(15{\text{ heads}})+\cdots +\Pr(20{\text{ heads}})\\&={\frac {1}{2^{20}}}\left[{\binom {20}{14}}+{\binom {20}{15}}+\cdots +{\binom {20}{20}}\right]={\frac {60\,460}{1\,048\,576}}\approx 0.058.\end{aligned}}}
гҒ“гҒ®зўәзҺҮгҒҜгҖҒ иЎЁгҒ«жңүеҲ©гҒӘжҘөз«ҜгҒӘзөҗжһңгҒ®гҒҝгӮ’иҖғж…®гҒ—гҒҹ p еҖӨгҒ§гҒӮгӮӢгҖӮгҒ“гӮҢгҒҜгҖҒзүҮеҒҙжӨңе®ҡ пјҲиӢұиӘһзүҲ пјү p еҖӨпјҲtwo-tailed p-valueпјүгӮ’гҖҒд»ЈгӮҸгӮҠгҒ«иЁҲз®—гҒҷгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгӮӢгҖӮе…¬жӯЈгҒӘгӮігӮӨгғігҒ®е ҙеҗҲгҖҒдәҢй …еҲҶеёғ гҒҜеҜҫз§°еҪўгҒЁгҒӘгӮӢгҒҹгӮҒгҖҒдёЎеҒҙ p еҖӨгҒҜеҚҳзҙ”гҒ«гҖҒеүҚиҝ°гҒ—гҒҹзүҮеҒҙ p еҖӨгҒ®2еҖҚгҒЁгҒӘгӮӢгҖӮгҒ“гҒ®дёЎеҒҙ p еҖӨгҒҜ 0.115 гҒ§гҒӮгӮӢгҖӮдёҠиЁҳгҒ®дҫӢгҒҜж¬ЎгҒ®гӮҲгҒҶгҒ«иЁҲз®—гҒҷгӮӢгҒ“гҒЁгҒҢгҒ§гҒҚгӮӢгҖӮ
её°з„Ўд»®иӘ¬ (H 0 )пјҡгӮігӮӨгғігҒҜе…¬жӯЈгҒ§гҒӮгӮҠгҖҒPr(heads) = 0.5 гҒ§гҒӮгӮӢ
жӨңе®ҡзөұиЁҲйҮҸпјҡиЎЁгҒҢеҮәгҒҹеӣһж•°
Оұж°ҙжә–пјҲжңүж„Ҹж°ҙжә–пјӣжҢҮе®ҡгҒ—гҒҹжңүж„Ҹе·®гҒ®й–ҫеҖӨпјүпјҡ0.05
иҰіжё¬еҖӨ O пјҡ20еӣһжҠ•гҒ’гҖҒиЎЁгҒҜ14еӣһ
H 0 гҒ«гҒҠгҒ‘гӮӢиҰіжё¬еҖӨ O гҒ®дёЎеҒҙ p еҖӨпјҡ 2 Г— min(Pr(иЎЁгҒ®еӣһж•° вүҘ 14еӣһ), Pr(иЎЁгҒ®еӣһж•° вүӨ 14еӣһ)) = 2 Г— min(0.058, 0.978) = 2 Г— 0.058 = 0.115Pr(иЎЁгҒ®еӣһж•° вүӨ 14еӣһ) = 1 вҲ’ Pr(иЎЁгҒ®еӣһж•° вүҘ 14еӣһ) + Pr(иЎЁгҒ®еӣһж•° = 14) = 1 вҲ’ 0.058 + 0.036 = 0.978 гҒЁгҒӘгӮӢгҖӮгҒҹгҒ гҒ—гҖҒгҒ“гҒ®дәҢй …еҲҶеёғгҒҜеҜҫз§°жҖ§гҒҢгҒӮгӮӢгҒҹгӮҒгҖҒ2гҒӨгҒ®зўәзҺҮгҒ®гҒҶгҒЎе°ҸгҒ•гҒ„ж–№гӮ’иҰӢгҒӨгҒ‘гӮӢиЁҲз®—гҒҜдёҚиҰҒгҒ§гҒӮгӮӢгҖӮгҒ“гҒ®дҫӢгҒ§гҒҜгҖҒиЁҲз®—гҒ—гҒҹ p еҖӨгҒҜ 0.05 гӮ’дёҠеӣһгҒЈгҒҰгҒҠгӮҠгҖҒгӮігӮӨгғігҒҢе…¬жӯЈгҒ§гҒӮгӮҢгҒ°гҖҒ95%гҒ®зўәзҺҮгҒ§иө·гҒ“гӮӢзҜ„еӣІеҶ…гҒ«гғҮгғјгӮҝгҒҢеҸҺгҒҫгӮӢгҒ“гҒЁгӮ’ж„Ҹе‘ігҒҷгӮӢгҖӮгҒ—гҒҹгҒҢгҒЈгҒҰгҖҒе„ӘдҪҚж°ҙжә– 0.05 гҒ§её°з„Ўд»®иӘ¬гҒҜжЈ„еҚҙгҒ•гӮҢгҒӘгҒ„гҖӮ
гҒ—гҒӢгҒ—гҖҒиЎЁгҒҢгӮӮгҒҶ1гҒӨеҮәгҒҰгҒ„гҒҹе ҙеҗҲгҖҒp еҖӨпјҲдёЎеҒҙпјүгҒҜ 0.0414пјҲ4.14%пјүгҒЁгҒӘгӮҠгҖҒгҒ“гҒ®дҫӢгҒ§гҒҜгҖҒжңүж„Ҹж°ҙжә– 0.05 гҒ§её°з„Ўд»®иӘ¬гҒҢжЈ„еҚҙгҒ•гӮҢгӮӢгҖӮ
гӮігӮӨгғігҒ®е…¬жӯЈжҖ§гӮ’жӨңе®ҡгҒҷгӮӢгҒҹгӮҒгҒ®еӨҡж®өйҡҺе®ҹйЁ“гӮ’иҖғгҒҲгӮӢгҒЁгҖҒгҖҢжҘөз«ҜгҖҚгҒЁгҒ„гҒҶиЁҖи‘үгҒ«гҒҜ2гҒӨгҒ®з•°гҒӘгӮӢж„Ҹе‘ігҒҢгҒӮгӮӢгҒ“гҒЁгҒҢжҳҺгӮүгҒӢгҒ«гҒӘгӮӢгҖӮе®ҹйЁ“гҒҢж¬ЎгҒ®гӮҲгҒҶгҒ«иЁӯиЁҲгҒ•гӮҢгҒҰгҒ„гӮӢгҒЁд»®е®ҡгҒҷгӮӢгҖӮ
гӮігӮӨгғігӮ’2еӣһжҠ•гҒ’гӮӢгҖӮ2еӣһгҒЁгӮӮиЎЁгҒҫгҒҹгҒҜиЈҸгҒҢеҮәгҒҹе ҙеҗҲгҖҒе®ҹйЁ“гҒҜзөӮдәҶгҒҷгӮӢгҖӮ
гҒқгҒҶгҒ§гҒӘгҒ„е ҙеҗҲгҒҜгҖҒгҒ•гӮүгҒ«4еӣһгӮігӮӨгғігӮ’жҠ•гҒ’гӮӢгҖӮ гҒ“гҒ®е®ҹйЁ“гҒ«гҒҜгҖҒиЎЁ2еӣһгҖҒиЈҸ2еӣһгҖҒиЎЁ5еӣһгҒЁиЈҸ1еӣһгҖҒ...гҖҒиЎЁ1еӣһгҒЁиЈҸ5еӣһгҒЁгҒ„гҒҶ7зЁ®йЎһгҒ®зөҗжһңгҒҢгҒӮгӮӢгҖӮгҒ„гҒҫгҖҢиЎЁ3еӣһгҒЁиЈҸ3еӣһгҖҚгҒЁгҒ„гҒҶзөҗжһңгҒ«гҒӨгҒ„гҒҰ p еҖӨгӮ’иЁҲз®—гҒҷгӮӢгҖӮ
жӨңе®ҡзөұиЁҲйҮҸгҒЁгҒ—гҒҰгҖҢиЎЁ/иЈҸгҖҚгӮ’з”ЁгҒ„гӮӢе ҙеҗҲгҖҒеё°з„Ўд»®иӘ¬гҒ®дёӢгҒ§гҒҜгҖҒдёЎеҒҙ pеҖӨгҒҜжӯЈзўәгҒ« 1гҖҒе·ҰзүҮеҒҙ pеҖӨгҒҜжӯЈзўәгҒ« 19/32гҖҒеҸізүҮеҒҙ pеҖӨгӮӮеҗҢж§ҳгҒЁгҒӘгӮӢгҖӮ
гҖҢиЎЁ3еӣһгҒЁиЈҸ3еӣһгҖҚгҒЁеҗҢгҒҳгҒӢгҒқгӮҢгӮҲгӮҠгӮӮдҪҺгҒ„зўәзҺҮгҒ®зөҗжһңгҒҢгҒҷгҒ№гҒҰгҖҢе°‘гҒӘгҒҸгҒЁгӮӮеҗҢгҒҳгҒҸгӮүгҒ„жҘөз«ҜгҖҚгҒЁгҒҝгҒӘгҒ•гӮҢгӮӢе ҙеҗҲгҖҒp еҖӨгҒҜжӯЈзўәгҒ« 1/2 гҒЁгҒӘгӮӢгҖӮ
гҒ—гҒӢгҒ—гҖҒдҪ•гҒҢиө·гҒ“гҒЈгҒҰгӮӮгӮігӮӨгғігӮ’6еӣһгҒ гҒ‘жҠ•гҒ’гӮӢгҒЁиЁҲз”»гҒ—гҒҹе ҙеҗҲгҖҒp еҖӨгҒ®2з•Әзӣ®гҒ®е®ҡзҫ©гҒӢгӮүгҖҒгҖҢиЎЁ3еӣһгҒЁиЈҸ3еӣһгҖҚгҒ® p еҖӨгҒҜжӯЈзўәгҒ« 1 гҒЁгҒӘгӮӢгҖӮ
гҒ“гҒ®гӮҲгҒҶгҒ«гҖҒгҖҢе°‘гҒӘгҒҸгҒЁгӮӮеҗҢгҒҳгҒҸгӮүгҒ„жҘөз«ҜгҖҚгҒЁгҒ„гҒҶ p еҖӨгҒ®е®ҡзҫ©гҒҜзҠ¶жіҒгҒ«еӨ§гҒҚгҒҸдҫқеӯҳгҒ—гҖҒе®ҹйҡӣгҒ«гҒҜиө·гҒ“гӮүгҒӘгҒӢгҒЈгҒҹгҒ“гҒЁгӮӮеҗ«гӮҒгҖҒе®ҹйЁ“иҖ…гҒҢгҖҢиЁҲз”»гҒ—гҒҹгҖҚеҶ…е®№гҒ«гӮҲгҒЈгҒҰгӮӮз•°гҒӘгӮӢгҖӮ
гӮёгғ§гғігғ»гӮўгғјгғҗгӮ№гғҺгғғгғҲ пјҲиӢұиӘһзүҲ пјү гғ”гӮЁгғјгғ«пјқгӮ·гғўгғігғ»гғ©гғ—гғ©гӮ№ гӮ«гғјгғ«гғ»гғ”гӮўгӮҪгғі гғӯгғҠгғ«гғүгғ»гғ•гӮЈгғғгӮ·гғЈгғј P еҖӨгҒ®з®—еҮәгҒҜ1700е№ҙд»ЈгҒ«йҒЎгӮҠгҖҒдәәгҒ®еҮәз”ҹжҷӮгҒ®жҖ§жҜ” пјҲиӢұиӘһзүҲ пјү [ 28] гӮёгғ§гғігғ»гӮўгғјгғҗгӮ№гғҺгғғгғҲ пјҲиӢұиӘһзүҲ пјү [ 29] [ 30] [ 31] [ 32] 82 гҖҒгҒӨгҒҫгӮҠ1/4,836,000,000,000,000,000,000,000гҒ§гҒӮгӮӢгҖӮгҒ“гӮҢгҒҜзҸҫд»ЈгҒ®иЁҖи‘үгҒ§иЁҖгҒҶ p еҖӨгҒ§гҒӮгӮӢгҖӮгҒ“гӮҢгҒҜжҘөгӮҒгҒҰе°ҸгҒ•гҒӘеҖӨгҒ§гҒӮгӮҠгҖҒгӮўгғјгғҗгӮ№гғҺгғғгғҲгҒҜгҖҒгҒ“гӮҢгӮ’еҒ¶з„¶гҒ§гҒҜгҒӘгҒҸзҘһгҒ®ж‘ӮзҗҶгҒ«гӮҲгӮӢгӮӮгҒ®гҒ гҒЁзөҗи«–гҒҘгҒ‘гҖҒгҖҢгҒ“гҒ®гҒ“гҒЁгҒӢгӮүгҖҒдё–з•ҢгӮ’ж”Ҝй…ҚгҒҷгӮӢгҒ®гҒҜеҒ¶з„¶гҒ§гҒҜгҒӘгҒҸгҖҒеүөйҖ гҒ§гҒӮгӮӢгҒЁгҒ„гҒҶзөҗи«–гҒҢе°ҺгҒҚеҮәгҒ•гӮҢгӮӢгҖӮгҖҚгҒЁиҝ°гҒ№гҒҹгҖӮзҸҫд»Јзҡ„гҒӘиЁҖгҒ„ж–№гӮ’гҒҷгӮҢгҒ°гҖҒеҪјгҒҜ p = 1/282 гҒ®жңүж„Ҹж°ҙжә–гҒ§гҖҒз”·е…җгҒЁеҘіе…җгҒ®еҮәз”ҹгҒҢеҗҢгҒҳзўәзҺҮгҒ§гҒӮгӮӢгҒЁгҒ„гҒҶеё°з„Ўд»®иӘ¬гӮ’жЈ„еҚҙгҒ—гҒҹгҖӮгӮўгғјгғҗгӮ№гғҺгғғгғҲгҒ®гҒ“гҒ®з ”究гҒЁд»–гҒ®з ”究гҒҜгҖҒгҖҢвҖҰ еҲқгӮҒгҒҰжңүж„Ҹе·®жӨңе®ҡгҒҢз”ЁгҒ„гӮүгӮҢгҒҹвҖҰ[ 33] [ 34] [ 30] з¬ҰеҸ·жӨңе®ҡ пјҲиӢұиӘһзүҲ пјү з¬ҰеҸ·жӨңе®ҡ В§ жӯҙеҸІ пјҲиӢұиӘһзүҲ пјү
еҗҢгҒҳз–‘е•ҸгҒҜеҫҢгҒ«гҖҒгғ”гӮЁгғјгғ«пјқгӮ·гғўгғігғ»гғ©гғ—гғ©гӮ№ гҒ«гӮҲгҒЈгҒҰеҸ–гӮҠдёҠгҒ’гӮүгӮҢгҖҒгғ©гғ—гғ©гӮ№гҒҜд»ЈгӮҸгӮҠгҒ«гғ‘гғ©гғЎгғҲгғӘгғғгӮҜжӨңе®ҡпјҲparametric testпјүгӮ’иЎҢгҒ„гҖҒдәҢй …еҲҶеёғ гҒ«еҹәгҒҘгҒ„гҒҰз”·жҖ§гҒ®еҮәз”ҹж•°гӮ’гғўгғҮгғ«еҢ–гҒ—гҒҹ[ 35]
1770е№ҙд»ЈгҖҒгғ©гғ—гғ©гӮ№гҒҜ50дёҮдәәиҝ‘гҒ„еҮәз”ҹзөұиЁҲгӮ’жӨңиЁҺгҒ—гҒҹгҖӮзөұиЁҲгҒ§гҒҜз”·е…җгҒ®ж•°гҒҢеҘіе…җгҒ®ж•°гӮ’дёҠеӣһгҒЈгҒҰгҒ„гҒҹгҖӮеҪјгҒҜ p еҖӨгҒ®иЁҲз®—гҒӢгӮүгҖҒжҘөз«ҜгҒӘзҸҫиұЎгҒҜзҸҫе®ҹгҒ®гӮӮгҒ®гҒ гҒҢиӘ¬жҳҺгҒ§гҒҚгҒӘгҒ„еҠ№жһңгҒ§гҒӮгӮӢгҒЁзөҗи«–гҒҘгҒ‘гҒҹгҖӮ
p еҖӨгҒҜгҖҒгӮ«гғјгғ«гғ»гғ”гӮўгӮҪгғі гҒҢгҖҒгӮ«гӮӨдәҢд№—еҲҶеёғ гӮ’з”ЁгҒ„гҒҹгҖҢгғ”гӮўгӮҪгғігҒ®гӮ«гӮӨдәҢд№—жӨңе®ҡ гҖҚгҒ§еҲқгӮҒгҒҰжӯЈејҸгҒ«е°Һе…ҘгҒ—гҖҒеӨ§ж–Үеӯ—гҒ® P гҒ§иЎЁиЁҳгҒ—гҒҹ[ 36] p еҖӨпјҲгҒ•гҒҫгҒ–гҒҫгҒӘ ПҮ 2 еҖӨгҒЁиҮӘз”ұеәҰпјүгҒҜ P гҒЁиЎЁиЁҳгҒ•гӮҢгҖҒElderton (1902) гҒ§з®—еҮәгҒ•гӮҢгҖҒPearson (1914 :xxxiвҖ“xxxiii, 26вҖ“28, Table XII) гҒ«гҒҫгҒЁгӮҒгӮүгӮҢгҒҹгҖӮ
гғӯгғҠгғ«гғүгғ»гғ•гӮЈгғғгӮ·гғЈгғј гҒҜзөұиЁҲгҒ«гҒҠгҒ‘гӮӢ p еҖӨгҒ®дҪҝгҒ„ж–№гӮ’жӯЈејҸеҢ–гҒ—гҖҒжҷ®еҸҠгҒ•гҒӣ[ 37] [ 38] [ 39] Statistical Methods for Research Workers пјҲз ”з©¶иҖ…гҒ®гҒҹгӮҒгҒ®зөұиЁҲзҡ„ж–№жі• пјҲиӢұиӘһзүҲ пјү p = 0.05 гӮ’зөұиЁҲзҡ„жңүж„ҸжҖ§гҒ®йҷҗз•ҢгҒЁгҒ—гҒҰжҸҗжЎҲгҒ—гҖҒгҒ“гӮҢгӮ’пјҲдёЎеҒҙжӨңе®ҡгҒЁгҒ—гҒҰпјүжӯЈиҰҸеҲҶеёғгҒ«йҒ©з”ЁгҒ—гҒҰгҖҒзөұиЁҲзҡ„жңүж„ҸжҖ§ гҒ®гҒҹгӮҒгҒ®пјҲжӯЈиҰҸеҲҶеёғгҒ«гҒҠгҒ‘гӮӢпјү2жЁҷжә–еҒҸе·®гҒ®гғ«гғјгғ«гӮ’з”ҹгҒҝгҒ гҒ—гҒҹ[ жіЁ 3] 68-95-99.7еүҮ пјү
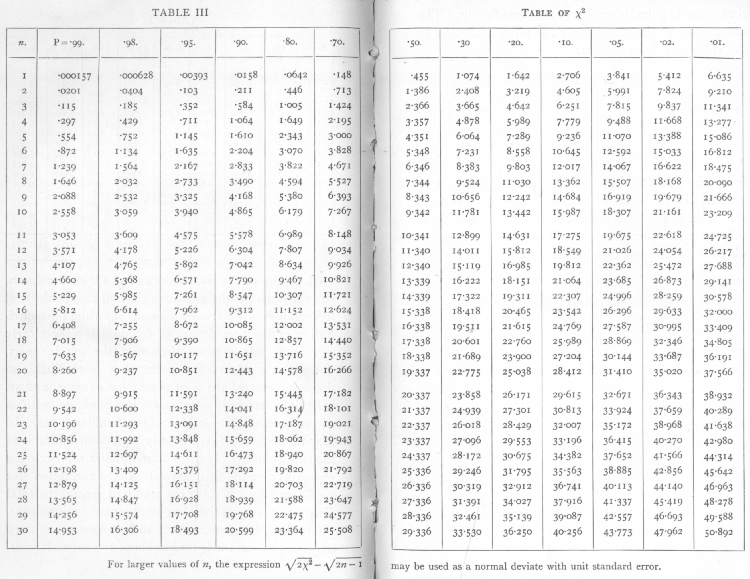
гҒ•гӮүгҒ«гҖҒElderton пјҲиӢұиӘһзүҲ пјү ПҮ 2 гҒЁ p гҒ®еҪ№еүІгҒҢйҖҶи»ўгҒ—гҒҹгҒ“гҒЁгҒ§гҒӮгӮӢгҖӮгҒӨгҒҫгӮҠгҖҒПҮ 2 пјҲгҒҠгӮҲгҒіиҮӘз”ұеәҰ n пјүгҒ®гҒ•гҒҫгҒ–гҒҫгҒӘеҖӨгҒ«гҒӨгҒ„гҒҰ p гӮ’иЁҲз®—гҒҷгӮӢгҒ®гҒ§гҒҜгҒӘгҒҸгҖҒзү№е®ҡгҒ® p еҖӨгҖҒе…·дҪ“зҡ„гҒ«гҒҜ 0.99гҖҒ0.98гҖҒ0.95гҖҒ0.90гҖҒ0.80гҖҒ0.70гҖҒ0.50гҖҒ0.30гҖҒ0.20гҖҒ0.10гҖҒ0.05гҖҒ0.02гҖҒ0.01 гҒ«еҜҫеҝңгҒҷгӮӢ ПҮ 2 еҖӨгӮ’иЁҲз®—гҒ—гҒҹ[ 42] ПҮ 2 гҒ®иЁҲз®—еҖӨгӮ’гӮ«гғғгғҲгӮӘгғ•еҖӨгҒЁжҜ”ијғгҒ§гҒҚгӮӢгӮҲгҒҶгҒ«гҒӘгӮҠпјҲp еҖӨиҮӘдҪ“гӮ’иЁҲз®—гҒ—гҖҒе ұе‘ҠгҒҷгӮӢгҒ®гҒ§гҒҜгҒӘгҒҸпјүгҖҒгҒқгҒ—гҒҰ p еҖӨпјҲзү№гҒ«0.05гҖҒ0.02гҖҒ0.01пјүгӮ’гӮ«гғғгғҲгӮӘгғ•еҖӨгҒЁгҒҷгӮӢгҒ“гҒЁгҒҢжҺЁеҘЁгҒ•гӮҢгҒҹгҖӮгҒқгҒ®еҫҢгҖҒFisher & Yates (1938) гҒ«гӮҲгӮҠеҗҢж§ҳгҒ®иЎЁгҒҢгҒҫгҒЁгӮҒгӮүгӮҢгҖҒгҒ“гҒ®жүӢжі•гҒҢе®ҡзқҖгҒ—гҒҹгҖӮ
е®ҹйЁ“гҒ®иЁӯиЁҲгҒЁи§ЈйҮҲгҒ«гҒҠгҒ‘гӮӢ p еҖӨгҒ®йҒ©з”ЁдҫӢгҒЁгҒ—гҒҰгҖҒгғ•гӮЈгғғгӮ·гғЈгғјгҒҜгҖҒж¬ЎгҒ®и‘—жӣёгҖҺThe Design of Experiments пјҲе®ҹйЁ“иЁҲз”»жі• пјҲиӢұиӘһзүҲ пјү p еҖӨгҒ®е…ёеһӢзҡ„гҒӘдҫӢгҒЁгҒ—гҒҰзҹҘгӮүгӮҢгӮӢгҖҢзҙ…иҢ¶гҒ®йҒ•гҒ„гҒ®гӮҸгҒӢгӮӢе©Ұдәә гҖҚгҒ®е®ҹйЁ“гӮ’зҙ№д»ӢгҒ—гҒҹгҖӮ
гҒӮгӮӢеҘіжҖ§пјҲгғҹгғҘгғӘгӮЁгғ«гғ»гғ–гғӘгӮ№гғҲгғ« пјҲиӢұиӘһзүҲ пјү гғ•гӮЈгғғгӮ·гғЈгғјгҒ®жӯЈзўәзўәзҺҮжӨңе®ҡ гҒ§гҖҒp еҖӨгҒҜ
1
/
(
8
4
)
=
1
/
70
≈ вүҲ -->
0.014
{\displaystyle 1/{\binom {8}{4}}=1/70\approx 0.014}
гғ•гӮЈгғғгӮ·гғЈгғјгҒҜ p = 0.05 гҒЁгҒ„гҒҶеҹәжә–гӮ’еҶҚеәҰиҝ°гҒ№гҖҒгҒқгҒ®ж №жӢ гӮ’иӘ¬жҳҺгҒ—гҒҹгҖӮ
жңүж„Ҹж°ҙжә–гҒ®еҹәжә–гҒЁгҒ—гҒҰ5%гӮ’з”ЁгҒ„гӮӢгҒ®гҒҜгҖҒе®ҹйЁ“иҖ…гҒ«гҒЁгҒЈгҒҰдёҖиҲ¬зҡ„гҒ§гҒӮгӮҠгҖҒдҫҝеҲ©гҒ§гӮӮгҒӮгӮӢгҖӮгҒӨгҒҫгӮҠгҒ“гҒ®еҹәжә–гҒ«йҒ”гҒ—гҒӘгҒ„зөҗжһңгӮ’гҒҷгҒ№гҒҰз„ЎиҰ–гҒ—гҖҒеҒ¶з„¶гҒҢе®ҹйЁ“зөҗжһңгҒ«гӮӮгҒҹгӮүгҒ—гҒҹеӨүеӢ•гҒ®еӨ§йғЁеҲҶгӮ’д»ҘйҷҚгҒ®иӯ°и«–гҒӢгӮүжҺ’йҷӨгҒҷгӮӢгҒЁгҒ„гҒҶж„Ҹе‘ігҒ§гҖҒе®ҹйЁ“иҖ…гҒ«гҒЁгҒЈгҒҰйғҪеҗҲгҒҢиүҜгҒ„гҖӮ
гҒҫгҒҹгҖҒеҪјгҒҜгҒ“гҒ®й–ҫеҖӨгӮ’е®ҹйЁ“иЁҲз”»гҒ«гӮӮйҒ©з”ЁгҒ—гҖҒгӮӮгҒ—6гҒӨгҒ®гӮ«гғғгғ—пјҲеҗ„3жқҜпјүгҒ—гҒӢжҸҗзӨәгҒ•гӮҢгҒҰгҒ„гҒӘгҒӢгҒЈгҒҹе ҙеҗҲгҖҒеҲҶйЎһгҒҢе®Ңе…ЁгҒ§гҒӮгҒЈгҒҹгҒЁгҒ—гҒҰгӮӮгҖҒp еҖӨгҒҜ
1
/
(
6
3
)
=
1
/
20
=
0.05
{\displaystyle 1/{\binom {6}{3}}=1/20=0.05}
p еҖӨгӮ’и§ЈйҮҲгҒҷгӮӢйҮҚиҰҒжҖ§гӮ’еј·иӘҝгҒ—гҒҹгҖӮ
гғ•гӮЈгғғгӮ·гғЈгғјгҒҜгҖҒи‘—жӣёгҒ®еҫҢгҒ®зүҲгҒ§гҖҒ科еӯҰзҡ„гҒӘзөұиЁҲзҡ„жҺЁи«–гҒ«гҒҠгҒ‘гӮӢ p еҖӨгҒ®дҪҝгҒ„ж–№гӮ’гғҚгӮӨгғһгғігғ»гғ”гӮўгӮҪгғіжі•гҒЁжҳҺзўәгҒ«жҜ”ијғгҒ—гҖҒгҒқгӮҢгӮ’гҖҢеҸ—гҒ‘е…ҘгӮҢжүӢй ҶгҖҚгҒЁе‘јгӮ“гҒ [ 45] p еҖӨгӮӮдҪҝз”ЁгҒ§гҒҚгҖҒгҒ•гӮүгҒӘгӮӢе®ҹйЁ“гҒ«гӮҲгҒЈгҒҰиЁјжӢ гҒ®еј·гҒ•гӮ’ж”№гӮҒгҖҒиҰӢзӣҙгҒҷгҒ“гҒЁгҒҢгҒ§гҒҚгӮӢгҒЁеј·иӘҝгҒ—гҒҹгҖӮгҒқгҒ®дёҖж–№гҖҒжұәе®ҡжүӢй ҶгҒҜжҳҺзўәгҒӘж„ҸжҖқжұәе®ҡгӮ’еҝ…иҰҒгҒЁгҒ—гҖҒгҒқгҒ®зөҗжһңгҖҒдёҚеҸҜи§ЈгҒӘиЎҢеӢ•гҒ«гҒӨгҒӘгҒҢгӮҠгҖҒгҒҫгҒҹгҒқгҒ®жүӢй ҶгҒҜйҒҺиӘӨгҒ®гӮігӮ№гғҲгҒ«еҹәгҒҘгҒ„гҒҰгҒҠгӮҠгҖҒ科еӯҰзҡ„з ”з©¶гҒ«гҒҜйҒ©з”ЁгҒ§гҒҚгҒӘгҒ„гҒЁжҢҮж‘ҳгҒ—гҒҹгҖӮ
E еҖӨгҒҜ2гҒӨгҒ®ж„Ҹе‘ігҒҢгҒӮгӮҠгҖҒгҒ©гҒЎгӮүгӮӮ p еҖӨгҒ«й–ўйҖЈгҒ—гҖҒеӨҡйҮҚжӨңе®ҡ гҒ«гҒҠгҒ„гҒҰеҪ№еүІгӮ’жһңгҒҹгҒ—гҒҰгҒ„гӮӢгҖӮ第дёҖгҒ«гҖҒp еҖӨгҒ«д»ЈгӮҸгӮӢдёҖиҲ¬зҡ„гҒ§гҖҒгӮҲгӮҠй ‘еј·гҒӘд»ЈжӣҝеҖӨпјҲиӢұиӘһзүҲ пјү жңҹеҫ… гҒ•гӮҢгӮӢеӣһж•°гҒ§гҒӮгӮӢ[ 46] p еҖӨгҒ®з©ҚгҒ§гҒӮгӮӢгҖӮ
q еҖӨпјҲиӢұиӘһзүҲ пјү еҒҪйҷҪжҖ§зҷәиҰӢзҺҮ пјҲиӢұиӘһзүҲ пјү p еҖӨгҒ®йЎһдјјеҖӨгҒ§гҒӮгӮӢ[ 47] еӨҡйҮҚд»®иӘ¬жӨңе®ҡ гҒ§дҪҝз”ЁгҒ•гӮҢгҖҒеҒҪйҷҪжҖ§зҺҮ пјҲиӢұиӘһзүҲ пјү жӨңеҮәеҠӣ гӮ’з¶ӯжҢҒгҒҷгӮӢгҒҹгӮҒгҒ«дҪҝгӮҸгӮҢгӮӢ[ 48]
ж–№еҗ‘жҖ§зўәзҺҮ пјҲиӢұиӘһзүҲ пјү pd пјүгҒҜгҖҒгғҷгӮӨгӮәзөұиЁҲеӯҰ гҒ«гҒҠгҒ‘гӮӢ p еҖӨгҒ®ж•°еҖӨзҡ„зӯүдҫЎгҒ§гҒӮгӮӢ[ 49] дәӢеҫҢеҲҶеёғ гҒ®гҒҶгҒЎдёӯеӨ®еҖӨгҒЁеҗҢгҒҳз¬ҰеҸ·гӮ’жҢҒгҒӨгӮӮгҒ®гҒ®еүІеҗҲгҒ«зӣёеҪ“гҒ—гҖҒйҖҡеёёгҒҜ50%гҒӢгӮү100%гҒ®й–“гҒ§еӨүеҢ–гҒ—гҖҒеҠ№жһңгҒҢжӯЈгҒ§гҒӮгӮӢгҒӢиІ гҒ§гҒӮгӮӢгҒӢгҒ®зўәе®ҹжҖ§гӮ’иЎЁгҒҷгҖӮ
第дәҢдё–д»Ј p еҖӨ гҒҜгҖҒжҘөгӮҒгҒҰе°ҸгҒ•гҒӘгҖҒе®ҹиіӘзҡ„гҒ«з„Ўй–ўдҝӮгҒӘеҠ№жһңйҮҸ пјҲиӢұиӘһзүҲ пјү p еҖӨгҒ®жҰӮеҝөгҒ®жӢЎејөгҒ§гҒӮгӮӢ[ 50]
^ з”ЁиӘһгҒ®гӮӨгӮҝгғӘгғғгӮҜдҪ“гҖҒеӨ§ж–Үеӯ—гҖҒгғҸгӮӨгғ•гғігҒ®дҪҝз”Ёжі•гҒҜгҒ•гҒҫгҒ–гҒҫгҒ§гҒӮгӮӢгҖӮгҒҹгҒЁгҒҲгҒ°гҖҒAMAгӮ№гӮҝгӮӨгғ« гҒ§гҒҜ"P value"гҖҒAPAгӮ№гӮҝгӮӨгғ« гҒ§гҒҜ"p value"гҖҒгӮўгғЎгғӘгӮ«зөұиЁҲеӯҰдјҡ пјҲASAпјүгҒ§гҒҜ"p -value"гҒЁиЎЁиЁҳгҒҷгӮӢгҖӮгҒ„гҒҡгӮҢгҒ®е ҙеҗҲгӮӮгҖҢpгҖҚгҒҜзўәзҺҮпјҲprobabilityпјүгӮ’иЎЁгҒҷгҖӮ[ 1]
^ зөҗжһңгҒ®зөұиЁҲзҡ„жңүж„ҸжҖ§гҒҜгҖҒзөҗжһңгҒҢзҸҫе®ҹдё–з•ҢгҒ§гӮӮеҪ“гҒҰгҒҜгҒҫгӮӢгҒ“гҒЁгӮ’ж„Ҹе‘ігҒҷгӮӢгӮҸгҒ‘гҒ§гҒҜгҒӘгҒ„гҖӮгҒҹгҒЁгҒҲгҒ°гҖҒгҒӮгӮӢи–¬гҒҢзөұиЁҲзҡ„гҒ«жңүж„ҸгҒӘеҠ№жһңгӮ’жҢҒгҒЈгҒҰгҒ„гҒҹгҒЁгҒ—гҒҰгӮӮгҖҒгҒқгҒ®еҠ№жһңгҒҢе°ҸгҒ•гҒҷгҒҺгҒҰж„Ҹе‘ігҒҢгҒӘгҒ„гҒ“гҒЁгӮӮгҒӮгӮӢгҖӮ
^ гӮҲгӮҠе…·дҪ“зҡ„гҒ«иЁҖгҒҲгҒ°гҖҒp = 0.05 гҒҜжӯЈиҰҸеҲҶеёғпјҲдёЎеҒҙжӨңе®ҡпјүгҒ®е ҙеҗҲгҖҒзҙ„ 1.96 жЁҷжә–еҒҸе·®гҒ«зӣёеҪ“гҒ—гҖҒ2жЁҷжә–еҒҸе·®гҒҜеҒ¶з„¶гҒ«и¶…гҒҲгӮӢеҸҜиғҪжҖ§гҒҢзҙ„ 1/22гҖҒгҒӨгҒҫгӮҠ p вүҲ 0.045 гҒ«зӣёеҪ“гҒҷгӮӢгҖӮгғ•гӮЈгғғгӮ·гғЈгғјгҒҜгҒ“гӮҢгӮүгҒ®иҝ‘дјјеҖӨгҒ«гҒӨгҒ„гҒҰиЁҖеҸҠгҒ—гҒҰгҒ„гӮӢгҖӮ
^ вҖңASA House Style вҖқ. Amstat News . American Statistical Association. 2022е№ҙ2жңҲ5ж—Ҙ й–ІиҰ§гҖӮ ^ Aschwanden C (2015е№ҙ11жңҲ24ж—Ҙ). вҖңNot Even Scientists Can Easily Explain P-values вҖқ. FiveThirtyEight . 25 September 2019жҷӮзӮ№гҒ®гӮӘгғӘгӮёгғҠгғ« гӮҲгӮҠгӮўгғјгӮ«гӮӨгғ–гҖӮ11 October 2019 й–ІиҰ§гҖӮ^ a b c d e Wasserstein RL; Lazar NA (7 March 2016). вҖңThe ASA's Statement on p-Values: Context, Process, and PurposeвҖқ. The American Statistician 70 (2): 129вҖ“133. doi :10.1080/00031305.2016.1154108 .
^ Hubbard R; Lindsay RM (2008). вҖңWhy P Values Are Not a Useful Measure of Evidence in Statistical Significance TestingвҖқ. Theory & Psychology 18 (1): 69вҖ“88. doi :10.1177/0959354307086923 . ^ MunafГІ MR; Nosek BA; Bishop DV; Button KS; Chambers CD; du Sert NP et al. (January 2017). вҖңA manifesto for reproducible scienceвҖқ . Nature Human Behaviour 1 (1): 0021. doi :10.1038/s41562-016-0021 . PMC 7610724 . PMID 33954258 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7610724/ . ^ Wasserstein, Ronald L.; Lazar, Nicole A. (2016-04-02). вҖңThe ASA Statement on p -Values: Context, Process, and PurposeвҖқ (иӢұиӘһ). The American Statistician 70 (2): 129вҖ“133. doi :10.1080/00031305.2016.1154108 . ISSN 0003-1305 . ^ a b Benjamini, Yoav; De Veaux, Richard D.; Efron, Bradley; Evans, Scott; Glickman, Mark; Graubard, Barry I.; He, Xuming; Meng, Xiao-Li et al. (2021-10-02). вҖңASA President's Task Force Statement on Statistical Significance and ReplicabilityвҖқ. Chance (Informa UK Limited) 34 (4): 10вҖ“11. doi :10.1080/09332480.2021.2003631 . ISSN 0933-2480 .
^ Neyman, Jerzy (1976). вҖңThe Emergence of Mathematical Statistics: A Historical Sketch with Particular Reference to the United StatesвҖқ . In Owen, D.B.. On the History of Statistics and Probability . Textbooks and Monographs. New York: Marcel Dekker Inc. p. 161. https://openlibrary.org/works/OL18334563W/On_the_history_of_statistics_and_probability?edition=key%3A/books/OL5206547M ^ Benjamin, Daniel J.; Berger, James O.; Johannesson, Magnus; Nosek, Brian A.; Wagenmakers, E.-J.; Berk, Richard; Bollen, Kenneth A.; Brembs, BjГ¶rn et al. (1 September 2017). вҖңRedefine statistical significanceвҖқ. Nature Human Behaviour 2 (1): 6вҖ“10. doi :10.1038/s41562-017-0189-z . hdl :10281/184094 PMID 30980045 . ^ a b Head ML; Holman L; Lanfear R; Kahn AT; Jennions MD (March 2015). вҖңThe extent and consequences of p-hacking in scienceвҖқ . PLOS Biology 13 (3): e1002106. doi :10.1371/journal.pbio.1002106 . PMC 4359000 . PMID 25768323 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4359000/ .
^ Simonsohn U; Nelson LD; Simmons JP (November 2014). вҖңp -Curve and Effect Size: Correcting for Publication Bias Using Only Significant ResultsвҖқ. Perspectives on Psychological Science 9 (6): 666вҖ“681. doi :10.1177/1745691614553988 . PMID 26186117 . ^ Bhattacharya B; Habtzghi D (2002). вҖңMedian of the p value under the alternative hypothesisвҖқ. The American Statistician 56 (3): 202вҖ“6. doi :10.1198/000313002146 . ^ Hung HM; O'Neill RT; Bauer P; KГ¶hne K (March 1997). вҖңThe behavior of the P-value when the alternative hypothesis is trueвҖқ . Biometrics 53 (1): 11вҖ“22. doi :10.2307/2533093 . JSTOR 2533093 . PMID 9147587 . https://zenodo.org/record/1235121 . ^ Nuzzo R (February 2014). вҖңScientific method: statistical errorsвҖқ. Nature 506 (7487): 150вҖ“152. Bibcode : 2014Natur.506..150N . doi :10.1038/506150a . PMID 24522584 . ^ Colquhoun D (November 2014). вҖңAn investigation of the false discovery rate and the misinterpretation of p-valuesвҖқ . Royal Society Open Science 1 (3): 140216. arXiv :1407.5296 . Bibcode : 2014RSOS....140216C . doi :10.1098/rsos.140216 . PMC 4448847 . PMID 26064558 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4448847/ . ^ Lee DK (December 2016). вҖңAlternatives to P value: confidence interval and effect sizeвҖқ . Korean Journal of Anesthesiology 69 (6): 555вҖ“562. doi :10.4097/kjae.2016.69.6.555 . PMC 5133225 . PMID 27924194 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5133225/ . ^ Ranstam J (August 2012). вҖңWhy the P-value culture is bad and confidence intervals a better alternativeвҖқ. Osteoarthritis and Cartilage 20 (8): 805вҖ“808. doi :10.1016/j.joca.2012.04.001 . PMID 22503814 . ^ Perneger TV (May 2001). вҖңSifting the evidence. Likelihood ratios are alternatives to P valuesвҖқ . BMJ 322 (7295): 1184вҖ“1185. doi :10.1136/bmj.322.7295.1184 . PMC 1120301 . PMID 11379590 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1120301/ . ^ Royall R (2004). вҖңThe Likelihood Paradigm for Statistical EvidenceвҖқ (иӢұиӘһ). The Nature of Scientific Evidence . pp. 119вҖ“152. doi :10.7208/chicago/9780226789583.003.0005 . ISBN 9780226789576 ^ Schimmack U (30 April 2015). вҖңReplacing p-values with Bayes-Factors: A Miracle Cure for the Replicability Crisis in Psychological Science вҖқ. Replicability-Index . 7 March 2017 й–ІиҰ§гҖӮ ^ Marden JI (December 2000). вҖңHypothesis Testing: From p Values to Bayes FactorsвҖқ. Journal of the American Statistical Association 95 (452): 1316вҖ“1320. doi :10.2307/2669779 . JSTOR 2669779 . ^ Stern HS (16 February 2016). вҖңA Test by Any Other Name: P Values, Bayes Factors, and Statistical InferenceвҖқ . Multivariate Behavioral Research 51 (1): 23вҖ“29. doi :10.1080/00273171.2015.1099032 . PMC 4809350 . PMID 26881954 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4809350/ . ^ Murtaugh PA (March 2014). вҖңIn defense of P valuesвҖқ . Ecology 95 (3): 611вҖ“617. Bibcode : 2014Ecol...95..611M . doi :10.1890/13-0590.1 . PMID 24804441 . https://zenodo.org/record/894459 . ^ Aschwanden C (7 March 2016). вҖңStatisticians Found One Thing They Can Agree On: It's Time To Stop Misusing P-Values вҖқ. FiveThirtyEight . 2016е№ҙ3жңҲ9ж—Ҙ й–ІиҰ§гҖӮ^ Amrhein V ; Korner-Nievergelt F; Roth T (2017). вҖңThe earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable researchвҖқ . PeerJ 5 : e3544. doi :10.7717/peerj.3544 . PMC 5502092 . PMID 28698825 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5502092/ . ^ Amrhein V ; Greenland S (January 2018). вҖңRemove, rather than redefine, statistical significanceвҖқ. Nature Human Behaviour 2 (1): 4. doi :10.1038/s41562-017-0224-0 . PMID 30980046 . ^ Colquhoun D (December 2017). вҖңThe reproducibility of research and the misinterpretation of p -valuesвҖқ . Royal Society Open Science 4 (12): 171085. doi :10.1098/rsos.171085 . PMC 5750014 . PMID 29308247 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5750014/ . ^ Brian E; Jaisson M (2007). вҖңPhysico-Theology and Mathematics (1710вҖ“1794)вҖқ . The Descent of Human Sex Ratio at Birth . Springer Science & Business Media. pp. 1 вҖ“25. ISBN 978-1-4020-6036-6 . https://archive.org/details/descenthumansexr00bria ^ Arbuthnot J (1710). вҖңAn argument for Divine Providence, taken from the constant regularity observed in the births of both sexesвҖқ . Philosophical Transactions of the Royal Society of London 27 (325вҖ“336): 186вҖ“190. doi :10.1098/rstl.1710.0011 . http://www.york.ac.uk/depts/maths/histstat/arbuthnot.pdf . ^ a b Conover WJ (1999). вҖңChapter 3.4: The Sign TestвҖқ. Practical Nonparametric Statistics (Third ed.). Wiley. pp. 157вҖ“176. ISBN 978-0-471-16068-7
^ Sprent P (1989). Applied Nonparametric Statistical Methods (Second ed.). Chapman & Hall. ISBN 978-0-412-44980-2 ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900 . Harvard University Press. pp. 225вҖ“226 . ISBN 978-0-67440341-3 ^ Bellhouse P (2001). вҖңJohn ArbuthnotвҖқ. Statisticians of the Centuries . Springer. pp. 39вҖ“42. ISBN 978-0-387-95329-8 ^ Hald A (1998). вҖңChapter 4. Chance or Design: Tests of SignificanceвҖқ. A History of Mathematical Statistics from 1750 to 1930 . Wiley. pp. 65 ^ Stigler SM (1986). The History of Statistics: The Measurement of Uncertainty Before 1900 . Harvard University Press. p. 134 . ISBN 978-0-67440341-3 ^ Pearson K (1900). вҖңOn the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random samplingвҖқ . Philosophical Magazine . Series 5 50 (302): 157вҖ“175. doi :10.1080/14786440009463897 . http://www.economics.soton.ac.uk/staff/aldrich/1900.pdf . ^ Biau, David Jean; Jolles, Brigitte M.; Porcher, RaphaГ«l (2010). вҖңP Value and the Theory of Hypothesis Testing: An Explanation for New ResearchersвҖқ . Clinical Orthopaedics and Related Research 468 (3): 885вҖ“892. doi :10.1007/s11999-009-1164-4 . ISSN 0009-921X . PMC 2816758 . PMID 19921345 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2816758/ . ^ Brereton, Richard G. (2021). вҖңP values and multivariate distributions: Non-orthogonal terms in regression modelsвҖқ (иӢұиӘһ). Chemometrics and Intelligent Laboratory Systems 210 : 104264. doi :10.1016/j.chemolab.2021.104264 . https://linkinghub.elsevier.com/retrieve/pii/S0169743921000320 . ^ Hubbard R; Bayarri MJ (2003), вҖңConfusion Over Measures of Evidence (p вҖІs) Versus Errors (ОұвҖІs) in Classical Statistical TestingвҖқ, The American Statistician 57 (3): 171вҖ“178 [p. 171], doi :10.1198/0003130031856 ^ Fisher 1925 , pp. 78вҖ“79, 98, Chapter IV. Tests of Goodness of Fit, Independence and Homogeneity; with Table of ПҮ 2 , Table III. Table of ПҮ 2 .^ Fisher 1971 , Section 12.1 Scientific Inference and Acceptance Procedures.^ вҖңDefinition of E-value вҖқ. National Institutes of Health . 2010е№ҙ5жңҲ17ж—Ҙ й–ІиҰ§гҖӮ ^ Storey JD (2003). вҖңThe positive false discovery rate: a Bayesian interpretation and the q-valueвҖқ. The Annals of Statistics 31 (6): 2013вҖ“2035. doi :10.1214/aos/1074290335 . ^ Storey JD; Tibshirani R (August 2003). вҖңStatistical significance for genomewide studiesвҖқ . Proceedings of the National Academy of Sciences of the United States of America 100 (16): 9440вҖ“9445. Bibcode : 2003PNAS..100.9440S . doi :10.1073/pnas.1530509100 . PMC 170937 . PMID 12883005 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC170937/ . ^ Makowski D; Ben-Shachar MS; Chen SH; LГјdecke D (10 December 2019). вҖңIndices of Effect Existence and Significance in the Bayesian FrameworkвҖқ . Frontiers in Psychology 10 : 2767. doi :10.3389/fpsyg.2019.02767 . PMC 6914840 . PMID 31920819 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6914840/ . ^ An Introduction to Second-Generation p-Values Jeffrey D. Blume, Robert A. Greevy, Valerie F. Welty, Jeffrey R. Smith &William D. Dupont https://www.tandfonline.com/doi/full/10.1080/00031305.2018.1537893
Denworth L (October 2019). вҖңA Significant Problem: Standard scientific methods are under fire. Will anything change?вҖқ. Scientific American 321 (4): 62вҖ“67 (63). "The use of p valuesstatistical significance of experimental results has contributed to an illusion of certainty and [to] reproducibility crises in many scientific fields . There is growing determination to reform statistical analysis... Some [researchers] suggest changing statistical methods, whereas others would do away with a threshold for defining "significant" results." Elderton, WP (1902). вҖңTables for Testing the Goodness of Fit of Theory to ObservationвҖқ . Biometrika 1 (2): 155вҖ“163. doi :10.1093/biomet/1.2.155 . https://zenodo.org/record/1431595 . Pearson, Karl (1914). вҖңOn the probability that two independent distributions of frequency are really samples of the same population, with special reference to recent work on the identity of Trypanosome strainsвҖқ. Biometrika 10 : 85вҖ“154. doi :10.1093/biomet/10.1.85 . Fisher, RA (1925). Statistical Methods for Research Workers . Edinburgh, Scotland: Oliver & Boyd. ISBN 978-0-05-002170-5 Fisher, RA (1971). The Design of Experiments ISBN 978-0-02-844690-5 . https://mimno.infosci.cornell.edu/info3350/readings/fisher.pdf Fisher, RA; Yates (1938). Statistical tables for biological, agricultural, and medical research hdl :2440/10701 . https://catalog.hathitrust.org/Record/001306237 Stigler SM (1986). The history of statistics : the measurement of uncertainty before 1900 ISBN 978-0-674-40340-6 . https://archive.org/details/historyofstatist00stig Hubbard R; Armstrong JS (2006). вҖңWhy We Don't Really Know What Statistical Significance Means: Implications for EducatorsвҖқ . Journal of Marketing Education 28 (2): 114вҖ“120. doi :10.1177/0273475306288399 . hdl :2092/413 гӮӘгғӘгӮёгғҠгғ« гҒ®May 18, 2006жҷӮзӮ№гҒ«гҒҠгҒ‘гӮӢгӮўгғјгӮ«гӮӨгғ–гҖӮ. https://web.archive.org/web/20060518054857if_/http://hops.wharton.upenn.edu/ideas/pdf/Armstrong/StatisticalSignificance.pdf . Hubbard R; Lindsay RM (2008). вҖңWhy P Values Are Not a Useful Measure of Evidence in Statistical Significance TestingвҖқ . Theory & Psychology 18 (1): 69вҖ“88. doi :10.1177/0959354307086923 . гӮӘгғӘгӮёгғҠгғ« гҒ®2016-10-21жҷӮзӮ№гҒ«гҒҠгҒ‘гӮӢгӮўгғјгӮ«гӮӨгғ–гҖӮ. https://web.archive.org/web/20161021014340if_/http://wiki.bio.dtu.dk/~agpe/papers/pval_notuseful.pdf 2015е№ҙ8жңҲ28ж—Ҙ й–ІиҰ§гҖӮ Stigler S (December 2008). вҖңFisher and the 5% levelвҖқ. Chance 21 (4): 12. doi :10.1007/s00144-008-0033-3 . Dallal, GE (2012). The Little Handbook of Statistical Practice гӮӘгғӘгӮёгғҠгғ« гҒ®2024-04-11жҷӮзӮ№гҒ«гҒҠгҒ‘гӮӢгӮўгғјгӮ«гӮӨгғ–гҖӮ. https://web.archive.org/web/20240411094738/http://www.jerrydallal.com/LHSP/p05.htm Biau DJ; Jolles BM; Porcher R (March 2010). вҖңP value and the theory of hypothesis testing: an explanation for new researchersвҖқ . Clinical Orthopaedics and Related Research 468 (3): 885вҖ“892. doi :10.1007/s11999-009-1164-4 . PMC 2816758 . PMID 19921345 . https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2816758/ . Reinhart A (2015). Statistics Done Wrong: The Woefully Complete Guide No Starch Press . p. 176. ISBN 978-1593276201 . http://statisticsdonewrong.com вҖңThe ASA President's Task Force Statement on Statistical Significance and ReplicabilityвҖқ. Annals of Applied Statistics 15 (3): 1084вҖ“1085. (2021). doi :10.1214/21-AOAS1501 . Benjamin, Daniel J.; Berger, James O.; Johannesson, Magnus; Nosek, Brian A.; Wagenmakers, E.-J.; Berk, Richard; Bollen, Kenneth A.; Brembs, BjГ¶rn et al. (1 September 2017). вҖңRedefine statistical significanceвҖқ. Nature Human Behaviour 2 (1): 6вҖ“10. doi :10.1038/s41562-017-0189-z . hdl :10281/184094 PMID 30980045 .
гӮҰгӮЈгӮӯгғЎгғҮгӮЈгӮўгғ»гӮігғўгғігӮәгҒ«гҒҜгҖҒ
PеҖӨ гҒ«й–ўйҖЈгҒҷгӮӢгӮ«гғҶгӮҙгғӘгҒҢгҒӮгӮҠгҒҫгҒҷгҖӮ















![{\displaystyle {\begin{aligned}&\Pr(14{\text{ heads}})+\Pr(15{\text{ heads}})+\cdots +\Pr(20{\text{ heads}})\\&={\frac {1}{2^{20}}}\left[{\binom {20}{14}}+{\binom {20}{15}}+\cdots +{\binom {20}{20}}\right]={\frac {60\,460}{1\,048\,576}}\approx 0.058.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1f2eebd3ba4473859aaacc3235a3929b3bf3b2bb)

.jpg)




{kind=link}