|
藏文
 藏文 藏文
藏文(藏語:བོད་ཡིག་,威利转写:bod yig,藏语拼音:Pöyig)是藏语、宗喀語、锡金语、普米语等语言的文字系统,基本上是一種元音附標文字,它根據古典藏語语音而建立,共三十个字母。目前通用的藏文罗马化方案为威利转写方案。除此之外,還有藏語拼音、《藏文拼音教材(拉薩音)》拼音方案、及THL拼音等羅馬化方案。
藏文是吐蕃時代公元7世紀由國王松贊干布派遣藏族語言學家吞弥·桑布扎到北印度學習梵文[1],回國後參照悉曇體梵文字母創製的。
藏文虽是为书写藏语而创制,但也和很多其它婆罗米系文字一样,能用于书写梵语。另外,在漢藏語系诸語中,藏文的历史长度、文献丰富程度都仅次于汉文。不过,这大量的文献中,绝大多数皆系佛教典籍,世俗文献不算太多。
藏文書寫方法
藏文每個音節有一個基字,確定該音節的中心輔音,基字上方或下方可以加元音附標表示不同的元音。基字上方有時有一個上加字,下方有時有一到兩個下加字,前邊有時有一個前加字,表示該音節的聲母是複輔音。複輔音的連接順序依次為前加字、上加字、基字、下加字。基字後邊有時有一到兩個后加字,表示該音節有一到兩個輔音韻尾。

 拉萨8路公交车上的显示屏显示藏文 拉萨8路公交车上的显示屏显示藏文
以下為藏文書寫的範例之一:

上面的藏文有一個音節“བསྒྲོནད”(威利转写:bsgrond),由前加字ba、上加字sa,基字ga,下加字ra,元音o、第一後加字na、第二後加字da構成。bsgrond是7世紀的藏語語音,隨著現在拉薩音裏複輔音以及部分韻尾的消失和聲調的出現,該詞已轉變讀成/ʈʂø̃˩˨/(藏语拼音:zhön,藏文拉萨音拼音:zhoenv)。
- 前加字只能是 ག /g/、 ད /d/、 བ /b/、 མ /m/、 འ /ɦ/。
- 上加字只能是 ཪ /r/、 ལ /l/、 ས /s/。
- 下加字只能是 ◌ྲ /r/、 ◌ /j/、 ◌ྭ /w/、 ◌ླ /l/ 和用於音譯梵文裏送氣濁輔音的送氣符號 ◌ྷ,有一個複輔音 གྲྭ /grwa/ 有兩個下加字 ◌ྲ /r/ 和 ◌ྭ /w/。
- 第一後加字只可能是 ཪ /r/、 ག /g/、 བ /b/、 མ /m/、 འ /ɦ/、 ང /ŋ/、 ས /s/、 ད /d/、 ན /n/、 ལ /l/。
- 第二後加字只可能是 ས /s/ 和 ད /d/,在現代藏語裏不再發音,ད /d/ 在現代藏語中已經不用。
另外,以下是藏文带头字(དབུ་ཅན་)和无头字(དབུ་མེད་)两种字体和国际拉丁文转写的列表:

基字
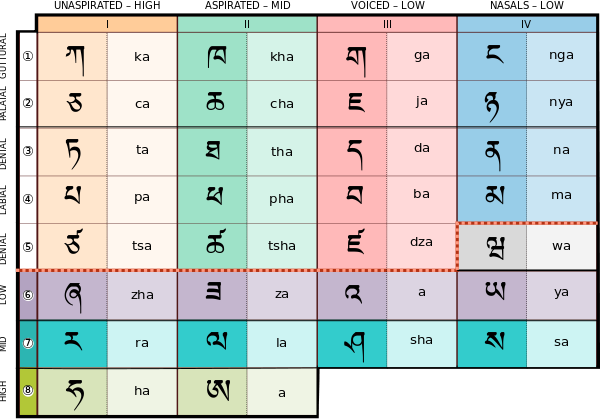
藏文的子音(གསལ་བྱེད་)除了第5行第4列的 ཝ (wa) 以外,字母表由最上方開始到第5行為止,在縱橫兩個方向的順序安排上具有語音學的意義。字典的排列順序即是由左而右、由上到下。
藏文子音字母表
|
|
第1列
不送氣 - 高
|
第2列
送氣 - 高
|
第3列
有聲 - 低
|
第4列
鼻音 - 低
|
| ①
|
ཀ
|
ka [k]
|
ཁ
|
kha [kʰ]
|
ག
|
ga [g]
|
ང
|
nga [ŋ]
|
| ②
|
ཅ
|
ca [ʨ]
|
ཆ
|
cha [ʨʰ]
|
ཇ
|
ja [dʑ]
|
ཉ
|
nya [ɲ]
|
| ③
|
ཏ
|
ta [t]
|
ཐ
|
tha [tʰ]
|
ད
|
da [d]
|
ན
|
na [n]
|
| ④
|
པ
|
pa [p]
|
ཕ
|
pha [pʰ]
|
བ
|
ba [b]
|
མ
|
ma [m]
|
| ⑤
|
ཙ
|
tsa [ʦ]
|
ཚ
|
tsha [ʦʰ]
|
ཛ
|
dza [dz]
|
ཝ
|
wa [w]
|
| ⑥(低)
|
ཞ
|
zha [ʑ]
|
ཟ
|
za [z]
|
འ
|
'a [ɦ]
|
ཡ
|
ya [j]
|
| ⑦(低低高高)
|
ར
|
ra [ɹ]
|
ལ
|
la [l]
|
ཤ
|
sha [ɕ]
|
ས
|
sa [s]
|
| ⑧(高)
|
ཧ
|
ha [h]
|
ཨ
|
a [無音價]
|
單音節的聲調有高平調與低平調(略為上升)兩種。必須注意以下兩點:
- 第4列(正確地來說應該是鼻音與接近音)的基字有前加字或上加字時,聲調將從低平調(或低升調)轉為高平調。(請參考下面的章節)
- 高平調與低平調有-ག(g)、-གས(gs)、-ད(d)、-བ(b)、-བས(bs)、-ངས(ngs)、-མས(ms)、-ས(s) 等後加字或再後加字時,聲調會往下降,形成高降調與低升降調。
另外,母音開頭的字使用最後的無音價字母ཨ來表示。
母音符號
由於基字本身帶有母音[a],因此需要其他四個母音符號(དབྱངས་)來書寫其他母音。另外,a [a]、o [o]、u [u]三個母音後面遇到舌尖音的後加字-ད(d)、-ན(n)、-ལ(l)、-ས(s)時,發音會變成 ä [ɛ]、ü [y]、ö [ø]。
| 母音符號 |
符號名稱 |
發音 |
例子
|
| ◌ |
無 |
[a] ([ɛ] -d, n, l, s) |
ཀ (ka)、ཏ (ta)、ཨ (a)
|
| ◌ི |
གི་གུ་ (gi gu) |
[i] |
ཀི (ki)、ཏི (ti)、ཨི (i)
|
| ◌ུ |
ཞབས་ཀྱུ་ (zhabs kyu) |
[u] ([y] -d, n, l, s) |
ཀུ (ku)、ཏུ (tu)、ཨུ (u)
|
| ◌ེ |
འགྲེང་པོ་ ('kreng po) |
[e] |
ཀེ (ke)、ཏེ (te)、ཨེ (e)
|
| ◌ོ |
ན་རོ་ (na ro) |
[o] ([ø] -d, n, l, s) |
ཀོ (ko)、ཏོ (to)、ཨོ (o)
|
其他
- 前加字:ག་ད་བ་མ་འ།
- 上加字:ར་ལ་ས།
- 下加字:ཡ་ར་ལ་ཝ།
- 第一後加字:ག་ང་ད་ན་བ་མ་འ་ར་ལ་ས།
- 第二後加字:ད་ས།
- 反體字(ལོག་ཡིག་):ཊ་ཋ་ཌ་ཎ་ཥ་ཀྵ།
- 併體字(མཐུག་ཡིག་):གྷ་དྷ་ཌྷ་བྷ་ཛྷ།
藏文字体
经过几千年的发展,藏文从吞弥桑布札创制开始至今,藏文字体已经发展出近几十种之多,但是总结起来主要为两大类,乌金体与乌梅体。[2]
二者的区别在于乌金体有冠体为其显著的特点,即每个字母最上一笔是横直的,字母排列时,上端必须在一条直线上,形似平顶帽。而乌梅体则省略了这条横线,此为两者最显著的区别。
在印刷与官方文书方面一般多使用乌金体,因其字体看起来比较大气故此。而乌梅体则较多的使用于手写录入。
藏文字母表
藏文字母的书写笔顺
以下图片以乌金体为例:
-
ཀ的笔顺
-
ཁ的笔顺
-
ག的笔顺
-
ང的笔顺
-
ཅ的笔顺
-
ཆ的笔顺
-
ཇ的笔顺
-
ཉ的笔顺
-
ཏ的笔顺
-
ཐ的笔顺
-
ད的笔顺
-
ན的笔顺
-
པ的笔顺
-
ཕ的笔顺(基于པ)
-
བ的笔顺
-
མ的笔顺
-
ཙ、ཚ、ཛ的笔顺(基于ཅ、ཆ、ཇ)
-
ཝ的笔顺
-
ཞ的笔顺
-
ཟ的笔顺
-
འ的笔顺
-
ཡ的笔顺
-
ར的笔顺
-
ལ的笔顺
-
ཤ的笔顺
-
ས的笔顺
-
ཧ的笔顺
-
ཨ的笔顺
巴尔蒂语扩充字母
巴尔蒂语有4个扩充的字母用于表示其特有的辅音:
| 巴尔蒂语扩充字母 |
罗马化 |
国际音标
|
| ཫ |
q |
/q/
|
| ཬ |
ɽ |
/ɽ/
|
| ཁ༹ |
x |
/χ/
|
| ག༹ |
ɣ |
/ʁ/
|
注释
- 目前尚沒有人明確地知道藏文 འ ('a-chung)在創製時的用途和所代表的發音是什麽。藏文中,對於C1VC2和C1C2V類型的音節,如果C1既可為前加字也可為基字,而C2既可為後加字又可為基字,爲了區分C1VC2與C1C2V這兩種不同的音節,就需要在書寫C1C2V時在V的位置填入 འ,此時 འ 似無實在作用,僅作為占位符使用。根據藏梵對音,འ 是用來標注梵文的長元音的,似乎也表明它沒有實際的發音用途。但在藏文的動詞變位方面,འ 卻是重要的構成現在時的前綴之一。在比較語言學上,它又似與漢語ɦ-前綴相對應。對於 འ 的用途,目前較流行的說法有:
- 認為它代表某種鼻音,用ɴ-表示。
- 認為它代表ɦ-或相近的發音。
- 認為它代表對後繼輔音的“前鼻化”(prenasalisation)。
- 認為它沒有具體對應的發音,或者它有多種不同的用途。
数字
藏文数字与阿拉伯数字一一对应,但写法不同。
| 藏文数字
|
༠ |
༡ |
༢ |
༣ |
༤ |
༥ |
༦ |
༧ |
༨ |
༩
|
| 阿拉伯数字
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9
|
| 藏文数字
|
༪ |
༫ |
༬ |
༭ |
༮ |
༯ |
༰ |
༱ |
༲ |
༳
|
| 阿拉伯数字
|
0.5 |
1.5 |
2.5 |
3.5 |
4.5 |
5.5 |
6.5 |
7.5 |
8.5 |
9.5
|
标点符号
- ༄〔段首〕
- ་〔音节结尾〕
- །〔句末〕
- ༎〔段末〕
- ༺〔左括号〕
- ༻〔右括号〕
- ༼〔左大括号〕
- ༽〔右大括号〕
- ༴〔重复符号〕
書写梵文
元音
| 天城文 |
IAST |
EWTS |
藏文字母 |
藏文附標 |
|
天城文 |
IAST |
EWTS |
藏文字母 |
藏文附標
|
| अ |
a |
a |
ཨ |
|
आ |
ā |
A |
ཨཱ |
ཱ
|
| इ |
i |
i |
ཨི |
ི
|
ई |
ī |
I |
ཨཱི |
ཱི
|
| उ |
u |
u |
ཨུ |
ུ
|
ऊ |
ū |
U |
ཨཱུ |
ཱུ
|
| ए |
e |
e |
ཨེ |
ེ
|
ऐ |
ai |
ai |
ཨཻ |
ཻ
|
| ओ |
o |
o |
ཨོ |
ོ
|
औ |
au |
au |
ཨཽ |
ཽ
|
| ऋ |
ṛ |
r-i |
རྀ |
ྲྀ
|
ॠ |
ṝ |
r-I |
རཱྀ |
ཷ
|
| ऌ |
ḷ |
l-i |
ལྀ |
ླྀ
|
ॡ |
ḹ |
l-I |
ལཱྀ |
ཹ
|
| अं |
aṃ |
aM |
ཨཾ |
ཾ
|
अः |
aḥ |
aH |
ཨཿ |
ཿ
|
| अँ |
a~M |
ཨྃ |
ྃ
|
輔音
| 天城文 |
IAST |
EWTS |
藏文字母 |
|
天城文 |
IAST |
EWTS |
藏文字母 |
|
天城文 |
IAST |
EWTS |
藏文字母 |
|
天城文 |
IAST |
EWTS |
藏文字母 |
|
天城文 |
IAST |
EWTS |
藏文字母
|
| क |
ka |
ka |
ཀ
|
ख |
kha |
kha |
ཁ
|
ग |
ga |
ga |
ག
|
घ |
gha |
g+ha |
གྷ
|
ङ |
ṅa |
nga |
ང
|
| च |
ca |
tsa |
ཙ
|
छ |
cha |
tsha |
ཚ
|
ज |
ja |
dza |
ཛ
|
झ |
jha |
dz+ha |
ཛྷ
|
ञ |
ña |
nya |
ཉ
|
| ट |
ṭa |
Ta |
ཊ
|
ठ |
ṭha |
Tha |
ཋ
|
ड |
ḍa |
Da |
ཌ
|
ढ |
ḍha |
D+ha |
ཌྷ
|
ण |
ṇa |
Na |
ཎ
|
| त |
ta |
ta |
ཏ
|
थ |
tha |
tha |
ཐ
|
द |
da |
da |
ད
|
ध |
dha |
d+ha |
དྷ
|
न |
na |
na |
ན
|
| प |
pa |
pa |
པ
|
फ |
pha |
pha |
ཕ
|
ब |
ba |
ba |
བ
|
भ |
bha |
bha |
བྷ
|
म |
ma |
ma |
མ
|
| य |
ya |
ya |
ཡ
|
र |
ra |
ra |
ར
|
ल |
la |
la |
ལ
|
व |
va |
wa |
ཝ
|
|
| श |
śa |
sha |
ཤ
|
ष |
ṣa |
Sha |
ཥ
|
स |
sa |
sa |
ས
|
ह |
ha |
ha |
ཧ
|
क्ष |
kṣa |
k+Sha |
ཀྵ
|
- च छ ज झ(ca cha ja jha)轉寫為 ཙ ཚ ཛ ཛྷ(tsa tsha dza dzha)是古往規定,現代轉寫也可用 ཅ ཆ ཇ ཇྷ(ca cha ja jha)。
| 天城文 |
IAST |
ETWS |
藏文字母
|
| च |
ca |
ca |
ཅ
|
| छ |
cha |
cha |
ཆ
|
| ज |
ja |
ja |
ཇ
|
| झ |
jha |
j+ha |
ཇྷ
|
罗马化
由于藏语和藏文在文字上不能一致对应,因此藏文的罗马化,有反应实际文字的罗马转写和反应实际语音的罗马拼音。
转写有国际流行的威利转写,美国国会图书馆的USLC转写。威利转写较USLC转写,不用上下标字母。而USLC转写在梵文转写可以和国际流行的梵文转写IAST通用,能准确地标示梵文字母。
拼音有藏語拼音、《藏文拼音教材(拉薩音)》拼音方案、及THL拼音等羅馬化方案。藏語拼音是中華人民共和國官方的藏語羅馬字母拼寫法,主要用於人名、地名的拼寫。
与现代拉萨音的对应
声母
藏語的7世紀複聲母向現代拉薩音單聲母的演變规律:
| 7世紀藏語發音的國際音標 |
當代拉薩話發音的國際音標
|
| spa, dpa, lpa |
pá
|
| rba, sba, dba, sbra |
pà
|
| lba, ɦba |
mpà
|
| ɦpʰa |
pʰá
|
| rma, sma, dma, smra |
má
|
| mra |
mà
|
| dba |
wá
|
| rta, lta, sta, twa, gta, bta, brta, blta, bsta, blda |
tá
|
| rda, sda, gda, bda, brda, bsda |
tà
|
| zla, bzla, lda, mda, ɦda |
ntà
|
| mtʰa, ɦtʰa |
tʰá
|
| dwa |
tʰà
|
| rna, sna, gna, brna, bsna, mna |
ná
|
| kla, gla, bla, rla, sla, brla, bsla |
lá
|
| lwa |
là
|
| rʦa, sʦa, ʦwa, gʦa, bʦa, brʦa, bsʦa |
ʦá
|
| rʣa, gʣa, brʣa |
ʦà
|
| mʣa, ɦʣa |
nʦà
|
| ʦʰwa, mʦʰa, ɦʦʰa |
ʦʰá
|
| sra, swa, gsa, bsa, bsra |
sá
|
| zwa, gza, bza |
sà
|
| kra, tra, pra, skra, dkra, dpra, bkra, bskra, bsra |
ʈʂá
|
| dgra, dbra, bgra, bsgra, sgra, sbra |
ʈʂà
|
| mgra, ɦgra, ɦdra, ɦbra |
ɳʈʂà
|
| kʰra, tʰra, pʰra, mkʰra, ɦkʰra, ɦpʰra |
ʈʂʰá
|
| gra, dra, bra, grwa |
ʈʂʰà
|
| hra |
ʂá
|
| rwa |
ʐà
|
| kja, rkja, skja, dkja, bkja, brkja, bskja |
cá
|
| rgja, sgja, dgja, bgja, brgja, bsgja |
cà
|
| mgja, ɦgja |
ɲcà
|
| kʰja, mkʰja, ɦkʰja |
cʰá
|
| gja |
cʰà
|
| gʨa, bʨa, lʨa, pja, dpja |
ʨá
|
| rʥa, brʥa, dbja |
ʨà
|
| lʥa, mʥa, ɦʥa, ɦbja |
ɲʨà
|
| mʨʰa, ɦʨʰa, pʰja, ɦpʰja |
ʨʰá
|
| bja |
ʨʰà
|
| ɕwa, gɕa, bɕa |
ɕá
|
| ʑwa, gʑa, bʑa |
ɕà
|
| rɲa, sɲa, gɲa, brɲa, bsɲa, mɲa |
ɲá
|
| ɲwa, mja |
ɲà
|
| g.ja |
já
|
| rka, lka, ska, kwa, dka, bka, brka, bska |
ká
|
| rga, sga, dga, bga, brga, bsga |
kà
|
| lga, mga, ɦga |
ŋkà
|
| kʰwa, mkʰa, ɦkʰa |
kʰá
|
| gwa |
kʰà
|
| rŋa, lŋa, sŋa, dŋa, brŋa, bsŋa, mŋa |
ŋá
|
| dba |
ʔá
|
| hwa |
há
|
韵母
见藏语#文字及语音。
计算机处理
編碼
藏文最初於1991年收入Unicode第1版,使用的區段為U+1000–U+104F。然而1993年Unicode 1.1版當中,這一區段被移除(後來在Unicode 3.0用於緬甸文)。1996年7月Unicode 2.0釋出後恢復對其支援。
藏文字母使用的區段為U+0F00–U+0FFF。藏文字母區段包括有文字、數字及多個標點符號及宗教文書上使用的特殊符號。下表詳列區段內的所有文字(你的瀏覽器需要支援藏文字母顯示):
藏文
Tibetan[1][2][3]
Unicode Consortium 官方碼表(PDF)
|
| |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F
|
| U+0F0x
|
ༀ
|
༁
|
༂
|
༃
|
༄
|
༅
|
༆
|
༇
|
༈
|
༉
|
༊
|
་
|
༌
NB
|
།
|
༎
|
༏
|
| U+0F1x
|
༐
|
༑
|
༒
|
༓
|
༔
|
༕
|
༖
|
༗
|
༘
|
༙
|
༚
|
༛
|
༜
|
༝
|
༞
|
༟
|
| U+0F2x
|
༠
|
༡
|
༢
|
༣
|
༤
|
༥
|
༦
|
༧
|
༨
|
༩
|
༪
|
༫
|
༬
|
༭
|
༮
|
༯
|
| U+0F3x
|
༰
|
༱
|
༲
|
༳
|
༴
|
༵
|
༶
|
༷
|
༸
|
༹
|
༺
|
༻
|
༼
|
༽
|
༾
|
༿
|
| U+0F4x
|
ཀ
|
ཁ
|
ག
|
གྷ
|
ང
|
ཅ
|
ཆ
|
ཇ
|
|
ཉ
|
ཊ
|
ཋ
|
ཌ
|
ཌྷ
|
ཎ
|
ཏ
|
| U+0F5x
|
ཐ
|
ད
|
དྷ
|
ན
|
པ
|
ཕ
|
བ
|
བྷ
|
མ
|
ཙ
|
ཚ
|
ཛ
|
ཛྷ
|
ཝ
|
ཞ
|
ཟ
|
| U+0F6x
|
འ
|
ཡ
|
ར
|
ལ
|
ཤ
|
ཥ
|
ས
|
ཧ
|
ཨ
|
ཀྵ
|
ཪ
|
ཫ
|
ཬ
|
|
|
|
| U+0F7x
|
|
ཱ
|
ི
|
ཱི
|
ུ
|
ཱུ
|
ྲྀ
|
ཷ
|
ླྀ
|
ཹ
|
ེ
|
ཻ
|
ོ
|
ཽ
|
ཾ
|
ཿ
|
| U+0F8x
|
ྀ
|
ཱྀ
|
ྂ
|
ྃ
|
྄
|
྅
|
྆
|
྇
|
ྈ
|
ྉ
|
ྊ
|
ྋ
|
ྌ
|
ྍ
|
ྎ
|
ྏ
|
| U+0F9x
|
ྐ
|
ྑ
|
ྒ
|
ྒྷ
|
ྔ
|
ྕ
|
ྖ
|
ྗ
|
|
ྙ
|
ྚ
|
ྛ
|
ྜ
|
ྜྷ
|
ྞ
|
ྟ
|
| U+0FAx
|
ྠ
|
ྡ
|
ྡྷ
|
ྣ
|
ྤ
|
ྥ
|
ྦ
|
ྦྷ
|
ྨ
|
ྩ
|
ྪ
|
ྫ
|
ྫྷ
|
ྭ
|
ྮ
|
ྯ
|
| U+0FBx
|
ྰ
|
ྱ
|
ྲ
|
ླ
|
ྴ
|
ྵ
|
ྶ
|
ྷ
|
ྸ
|
ྐྵ
|
ྺ
|
ྻ
|
ྼ
|
|
྾
|
྿
|
| U+0FCx
|
࿀
|
࿁
|
࿂
|
࿃
|
࿄
|
࿅
|
࿆
|
࿇
|
࿈
|
࿉
|
࿊
|
࿋
|
࿌
|
|
࿎
|
࿏
|
| U+0FDx
|
࿐
|
࿑
|
࿒
|
࿓
|
࿔
|
࿕
|
࿖
|
࿗
|
࿘
|
࿙
|
࿚
|
|
|
|
|
|
| U+0FEx
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| U+0FFx
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注釋
- 1.^ 依據 Unicode 14.0
- 2.^ 灰色區域表示未分配的碼位
- 3.^ 碼位U+0F77和U+0F79於5.2版本時廢棄
|
藏文字母在统一码(Unicode)的編碼空間由 0F40 至 0F69。茲表列如下:
Unicode
拉丁字母
转写
|
藏文
字母
|
統一碼
|
|
Unicode
拉丁字母
轉寫
|
藏文
字母
|
統一碼
|
|
Unicode
拉丁字母
轉寫
|
藏文
字母
|
統一碼
|
|
Unicode
拉丁字母
轉寫
|
藏文
字母
|
統一碼
|
|
Unicode
拉丁字母
轉寫
|
藏文
字母
|
統一碼
|
| ka |
ཀ
|
0F40
|
kha |
ཁ
|
0F41
|
ga |
ག
|
0F42
|
gha |
གྷ
|
0F43
|
nga |
ང
|
0F44
|
| ca |
ཅ
|
0F45
|
cha |
ཆ
|
0F46
|
ja |
ཇ
|
0F47
|
jha |
ཇྷ
|
0F48
|
nya |
ཉ
|
0F49
|
| tta |
ཊ
|
0F4A
|
ttha |
ཋ
|
0F4B
|
dda |
ཌ
|
0F4C
|
ddha |
ཌྷ
|
0F4D
|
nna |
ཎ
|
0F4E
|
| ta |
ཏ
|
0F4F
|
tha |
ཐ
|
0F50
|
da |
ད
|
0F51
|
dha |
དྷ
|
0F52
|
na |
ན
|
0F53
|
| pa |
པ
|
0F54
|
pha |
ཕ
|
0F55
|
ba |
བ
|
0F56
|
bha |
བྷ
|
0F57
|
ma |
མ
|
0F58
|
| tsa |
ཙ
|
0F59
|
tsha |
ཚ
|
0F5A
|
dza |
ཛ
|
0F5B
|
dzha |
ཛྷ
|
0F5C
|
wa |
ཝ
|
0F5D
|
| zha |
ཞ
|
0F5E
|
za |
ཟ
|
0F5F
|
-a |
འ
|
0F60
|
ya |
ཡ
|
0F61
|
ra |
ར
|
0F62
|
| la |
ལ
|
0F63
|
sha |
ཤ
|
0F64
|
ssa |
ཥ
|
0F65
|
sa |
ས
|
0F66
|
ha |
ཧ
|
0F67
|
| a |
ཨ
|
0F68
|
kssa |
ཀྵ
|
0F69
|
|
|
|
|
|
|
|
|
|
信息处理用标准
1997年9月2日,中华人民共和国国家技术监督局发布了《中华人民共和国国家标准GB 16959—1997 信息技术 信息交换用藏文编码字符集 基本集》(以下简称“《基本集》”),于1998年1月1日起实施。该标准由中华人民共和国电子工业部提出,全国信息技术标准化技术委员会归口,起草单位为西藏自治区藏语文工作指导委员会办公室、西藏大学、西藏自治区技术监督局、西北民族学院、青海师范大学。[3]该标准是中华人民共和国第一个少数民族语言文字的信息处理用国际标准,也是中华人民共和国现行全部藏文信息处理用国家标准。[4]
《基本集》收录的藏文字母,可组成任意藏文词句,包括藏文古籍的文字。1997年《基本集》刚刚发布时,因技术局限,藏文字母的上下叠加构造无法方便处理,难以实现藏文的动态组合,故后来西藏大学藏文信息技术研究中心陆续制定6项藏文信息处理交换标准国家标准。2007年,共有8个国际标准及国家标准获得中华人民共和国教育部批准。经过上述完善,《基本集》已成为如今国际普遍应用的标准,微软、苹果等国际软件企业开发藏文产品时,均依照该标准,如微软从Windows7系统开始便依照该标准支持了藏文字母的上下叠加构造。[4][5]
鍵盤輸入
1984年,西北民族大学教授、中国民族信息技术研究院院长于洪志主持开发了“藏文信息处理系统”、“藏文输入系统”、“藏文操作系统”等。[6]
 藏语键盘布局 藏语键盘布局
现有的藏文信息处理中的键盘均是依据西藏大学藏文信息技术研究中心确定的,包括微软2007年推出的Windows Vista操作系统(Operating System,OS)中藏文输入系统也对此基本遵循。过去,包括1998年实施的《基本集》在内,藏文的上下叠加构造无法方便实现;但在西藏大学藏文信息技术研究中心推出的藏文信息处理用国家标准实现了藏文的上下叠加构造之后,藏文的横向组合与纵向叠加已经全部实现。[5]
1998年实施《基本集》后,西北民族学院计算机教师和藏文教师用一年多完成了“藏汉双语信息处理系统”,包括藏文构件集编码、字型、格萨尔信息系统、藏文历算软件、藏药检索、藏医自动诊断、藏文字频统计、藏文办公自动化、藏文数据统计等9个子系统。[6]
2007年11月,甘肃省推出藏文彩信手机报,成为中国第一份藏文彩信手机报。[6]在1998年实施的《基本集》的基础上,西南民族大学民族文字信息处理研究所组成手写藏文手机输入法和藏文字库的课题组,创建24点阵的藏文点阵字库,翻译5000多条手写藏文手机术语。2009年,西南民族大学与北京网道信通科技发展有限公司共同研制的世界上第一款手写藏文手机正式推出,包括GSM手机和CDMA手机两种。[7]2012年6月,中国电信西藏公司藏文版手机上市,受到西藏自治区藏族民众特别是藏传佛教僧众及农牧民的欢迎。[8]
西藏大学藏文信息技术研究中心的主要研究方向是藏文信息技术基础理论和应用,重点研发了藏文字符编码、输入法、字库(符合国际标准的最大藏文字库,支持梵音藏文相互转写,支持微软及Linux操作系统)、操作系统(2008年与中国科学院共同研发了藏文版的红旗操作系统,为世界第一款从底层编码的藏文操作系统)、上网软件、办公软件、文字识别(藏文OCR文字识别系统);此外还包括:藏语自然语言处理、藏文模式识别、藏文信息安全、藏文数字媒体技术与工程、藏文嵌入式。该中心研制的新一代藏文软件已应用到西藏自治区第二代身份证制作中。拉萨市公交车语音报站系统即该中心研制的藏文嵌入式的应用。该中心还将建设一个大规模藏语语料库,以推出基于安卓操作系统的藏文智能手机,并能支持藏文的手写及语音输入技术。[4]
参考文献
參閲
外部連結
|
|




_(14298540735).jpg)






















