![]() SQL ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ฟผ๋ฆฌ์ ์.
SQL ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ฟผ๋ฆฌ์ ์.
๋ฐ์ดํฐ๋ฒ ์ด์ค(์์ด: database, DB)๋ ์ฌ๋ฌ ์ฌ๋์ด ๊ณต์ ํ์ฌ ์ฌ์ฉํ ๋ชฉ์ ์ผ๋ก ์ฒด๊ณํํด ํตํฉ, ๊ด๋ฆฌํ๋ ๋ฐ์ดํฐ์ ์งํฉ์ด๋ค.[1] ์์ฑ๋ ๋ชฉ๋ก์ผ๋ก์จ ์ฌ๋ฌ ๋ฐ์ดํฐ ๋ฒ ์ด์ค ๊ด๋ฆฌ ์์คํ
(DBMS)์ ํตํฉ๋ ์ ๋ณด๋ค์ ์ ์ฅํ์ฌ ์ด์ํ ์ ์๋ ๊ณต์ฉ ๋ฐ์ดํฐ๋ค์ ๋ฌถ์์ด๋ค. ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ์ํด ์๋ ๋ชจ๋ธ์ ๋ค์ํ๋ค.
์ญ์ฌ
1950๋
๋์ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ผ๋ ์ฉ์ด๊ฐ ๋ฏธ๊ตญ์์ ์ฒ์ ์ฌ์ฉ๋์์ผ๋ฉฐ, ๋ณธ๋๋ ๊ตฐ๋น์ ์ง์ค์ ยทํจ์จ์ ๊ด๋ฆฌ๋ฅผ ์ํด ์ปดํจํฐ๋ฅผ ํ์ฉํ ๋์๊ด ๊ฐ๋
์ ๊ฐ๋ฐํ๋ฉด์ ์ด๋ฅผ '๋ฐ์ดํฐ์ ๊ธฐ์ง'๋ผ๋ ๋ป์ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ก ์ผ์ปฌ์๋ค. ์ดํ 1965๋
์์คํ
๋๋ฒจ๋กํ์ฌ๊ฐ 2์ฐจ๋ก ๊ฐ์ตํ '์ปดํจํฐ ์ค์ฌ ๋ฐ์ดํฐ๋ฒ ์ด์ค ์์คํ
'์ด๋ผ๋ ์ฌํฌ์ง์์์ ์ฒ์ ์ฌ์ฉํ์๋ค.[2]
ํ๋ก์ธ์, ์ปดํจํฐ ๋ฉ๋ชจ๋ฆฌ, ์ปดํจํฐ ์คํ ๋ฆฌ์ง, ์ปดํจํฐ ๋คํธ์ํฌ ๋ถ์ผ์์ ๊ธฐ์ ์ด ์ง์ ๋จ์ ๋ฐ๋ผ, ๋ฑ๊ธ ์์ผ๋ก ๋ฐ์ดํฐ๋ฒ ์ด์ค ๋ฐ ๊ฐ DBMS์ ํฌ๊ธฐ, ๊ธฐ๋ฅ, ์ฑ๋ฅ์ด ์์นํด์๋ค. ๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ธฐ์ ์ ๋ฐ์ ์ ๋ฐ์ดํฐ ๋ชจ๋ธ์ด๋ ๊ตฌ์กฐ์ ๋ฐ๋ผ ์ธ ๊ฐ์ ์๋๋ก ๋๋๋ค(๋ด๋น๊ฒ์ด์
๋ ๋ฐ์ดํฐ๋ฒ ์ด์ค, SQL/๊ด๊ณํ ๋ฐ์ดํฐ๋ฒ ์ด์ค, ๊ด๊ณํ ์ดํ ๋ฐ์ดํฐ๋ฒ ์ด์ค).
์ฃผ๊ฐ ๋๋ 2๊ฐ์ ๋ด๋น๊ฒ์ด์
๋ ๋ฐ์ดํฐ ๋ชจ๋ธ์ IBM์ IMS ์์คํ
์ ์ ํ์ ๋ณธ๋ณด๊ธฐ๊ฐ ๋๋ ๊ณ์ธตํ ๋ชจ๋ธ, ๊ทธ๋ฆฌ๊ณ IDMS์ ๊ฐ์ ์๋ง์ ์ ํ๋ค์ ๊ตฌํ๋ CODASYL ๋ชจ๋ธ (๋คํธ์ํฌ ๋ชจ๋ธ)์ด๋ค.
1970๋
์ ์๋๊ฑฐ F. ์ปค๋๊ฐ ์ฒ์ ์ ์ํ ๊ด๊ณํ ๋ชจ๋ธ์ ์์ฉ ํ๋ก๊ทธ๋จ๋ค์ด ๋ท๋ฐ๋ฅด๋ ๋งํฌ๊ฐ ์๋ ๋ด์ฉ์ ๊ธฐ์ค์ผ๋ก ๋ฐ์ดํฐ๋ฅผ ๊ฒ์ํด์ผ ํ๋ค๊ณ ์ฃผ์ฅํ๋ฉด์ ์ด๋ฌํ ์ ํต์์ ์ถ๋ฐํ๋ค. ๊ด๊ณํ ๋ชจ๋ธ์ ๊ธ์ ์ถ๋ฉ๋ถ ์คํ์ผ์ ํ๋ค์ ๋ชจ์์ ์ด์ฉํ๋ฉฐ, ๊ฐ๊ฐ์ ๋ค๋ฅธ ํ์
์ ์ํฐํฐ๋ฅผ ์ํด ์ฌ์ฉ๋๋ค. 1980๋
๋ ๋ค์ด์์ผ ์ปดํจํ
ํ๋์จ์ด๊ฐ ๋น๋ก์ ๊ด๊ณํ ์์คํ
(DBMS + ์ ํ๋ฆฌ์ผ์ด์
)์ ํญ๋์ ๋ฐฐ์น๋ฅผ ๊ฐ๋ฅ์ผ ํ ๋งํผ ๊ฐ๋ ฅํด์ก๋ค. ๊ทธ๋ฌ๋ 1990๋
๋ ์ด ๋ค์ด์ ๋ชจ๋ ๋ํ ๋ฐ์ดํฐ ์ฒ๋ฆฌ ์ ํ๋ฆฌ์ผ์ด์
์ ๊ด๊ณํ ์์คํ
๋ค์ด ์ง๋ฐฐํ๊ฒ ๋์์ผ๋ฉฐ 2015๋
๊ธฐ์ค์ผ๋ก ์ฌ์ ํ ์ํฉ์ ๋์ผํ๋ค. : IBM DB2, ์ค๋ผํด, MySQL, ๋ง์ดํฌ๋ก์ํํธ SQL ์๋ฒ๋ ์ต์์ DBMS์ด๋ค.[4] ์ง๋ฐฐ์ ์ธ ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ธ์ด, ๊ณง ๊ด๊ณํ ๋ชจ๋ธ์ ์ํ ํ์คํ๋ SQL์ ๋ค๋ฅธ ๋ฐ์ดํฐ ๋ชจ๋ธ์ ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ธ์ด๋ค์ ์ํฅ์ ๋ฏธ์ณค๋ค.
๊ฐ์ฒด ์งํฅ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ ๊ฐ์ฒด ์งํฅ ์ํผ๋์ค ๋ถ์ผ์น์ ๋ถํธํจ์ ๊ทน๋ณตํ๊ณ ์ 1980๋
๋์ ๊ฐ๋ฐ๋์์ผ๋ฉฐ, ์ด๋ก ์ธํด "๊ด๊ณํ ์ดํ"(post-relational)๋ผ๋ ์ฉ์ด๊ฐ ๋ง๋ค์ด์ก๊ณ ํ์ด๋ธ๋ฆฌ๋ ๊ฐ์ฒด ๊ด๊ณ ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ๊ฐ๋ฐ๋ก๋ ์ด์ด์ก๋ค.
2000๋
๋ ๋ง์ ๊ด๊ณํ ์ดํ์ ์ฐจ์ธ๋ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ NoSQL ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ก ์๋ ค์ง๊ฒ ๋์์ผ๋ฉฐ, ๊ณ ์์ ํค-๊ฐ ์คํ ์ด, ๋ํ๋จผํธ ์งํฅ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ฅผ ๋์
ํ์๋ค. NewSQL ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ผ๋ ๊ฒฝ์๋ ฅ ์๋ ์ฐจ์ธ๋ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ ์์ฉ ๊ด๊ณํ DBMS ๋๋น NoSQL์ ๋์ ์ฑ๋ฅ์ ๋ถํฉํ๋ฉด์ ๊ด๊ณํ/SQL ๋ชจ๋ธ์ ๋ณด์ ํ๋ ์๋ก์ด ๊ตฌํ์ ์๋ํ์๋ค.
๋ฐ์ดํฐ๋ฒ ์ด์ค์ ๊ฐ๋
์ฌ๋ฌ ์ฌ๋์ด ๊ณต์ ํ๊ณ ์ฌ์ฉํ ๋ชฉ์ ์ผ๋ก ํตํฉ ๊ด๋ฆฌ๋๋ ์ ๋ณด์ ์งํฉ์ด๋ค. ๋
ผ๋ฆฌ์ ์ผ๋ก ์ฐ๊ด๋ ํ๋ ์ด์์ ์๋ฃ์ ๋ชจ์์ผ๋ก ๊ทธ ๋ด์ฉ์ ๊ณ ๋๋ก ๊ตฌ์กฐํํจ์ผ๋ก์จ ๊ฒ์๊ณผ ๊ฐฑ์ ์ ํจ์จํ๋ฅผ ๊พํ ๊ฒ์ด๋ค. ์ฆ, ๋ช ๊ฐ์ ์๋ฃ ํ์ผ์ ์กฐ์ง์ ์ผ๋ก ํตํฉํ์ฌ ์๋ฃ ํญ๋ชฉ์ ์ค๋ณต์ ์์ ๊ณ ์๋ฃ๋ฅผ ๊ตฌ์กฐํํ์ฌ ๊ธฐ์ต์์ผ ๋์ ์๋ฃ์ ์งํฉ์ฒด๋ผ๊ณ ํ ์ ์๋ค.
๊ณต๋ ์๋ฃ๋ก์ ๊ฐ ์ฌ์ฉ์๋ ๊ฐ์ ๋ฐ์ดํฐ๋ผ ํ ์ง๋ผ๋ ๊ฐ์์ ์์ฉ ๋ชฉ์ ์ ๋ฐ๋ผ ๋ค๋ฅด๊ฒ ์ฌ์ฉํ ์ ์๋ค.
- ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ํน์ง
- ์ค์๊ฐ ์ ๊ทผ์ฑ
- ์ง์์ ์ธ ๋ณํ
- ๋์ ๊ณต์
- ๋ด์ฉ์ ๋ํ ์ฐธ์กฐ
- ๋ฐ์ดํฐ ๋
ผ๋ฆฌ์ ๋
๋ฆฝ์ฑ
๋ฐ์ดํฐ๋ฒ ์ด์ค์ ์ฅ๋จ์
- ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ฅ์
- ๋ฐ์ดํฐ ์ค๋ณต ์ต์ํ
- ๋ฐ์ดํฐ ๊ณต์
- ์ผ๊ด์ฑ, ๋ฌด๊ฒฐ์ฑ, ๋ณด์์ฑ ์ ์ง
- ์ต์ ์ ๋ฐ์ดํฐ ์ ์ง
- ๋ฐ์ดํฐ์ ํ์คํ ๊ฐ๋ฅ
- ๋ฐ์ดํฐ์ ๋
ผ๋ฆฌ์ , ๋ฌผ๋ฆฌ์ ๋
๋ฆฝ์ฑ
- ์ฉ์ดํ ๋ฐ์ดํฐ ์ ๊ทผ
- ๋ฐ์ดํฐ ์ ์ฅ ๊ณต๊ฐ ์ ์ฝ
- ๋ฐ์ดํฐ๋ฒ ์ด์ค ๋จ์
- ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ ๋ฌธ๊ฐ ํ์
- ๋ง์ ๋น์ฉ ๋ถ๋ด
- ๋ฐ์ดํฐ ๋ฐฑ์
๊ณผ ๋ณต๊ตฌ๊ฐ ์ด๋ ค์
- ์์คํ
์ ๋ณต์กํจ
- ๋์ฉ๋ ๋์คํฌ๋ก ์์ธ์ค๊ฐ ์ง์ค๋๋ฉด ๊ณผ๋ถํ ๋ฐ์
๋ฐ์ดํฐ๋ฒ ์ด์ค ๋ชจ๋ธ
์ค์ ์ ์ธ ๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ตฌํ์ ์ํ ํ์ฌ ๋ช๋ช ๊ฐ๋
ํ๋ ๋
ผ๋ฆฌ์ ๋ฐ์ดํฐ ๋ชจ๋ธ์ ๋ค์๊ณผ ๊ฐ๋ค:
๊ด๊ณ ๋ฐ์ดํฐ ๋ชจ๋ธ
๊ด๊ณ ๋ฐ์ดํฐ๋ชจ๋ธ (relational datamodel)์ ๋ฐ์ดํฐ ๋ชจ๋ธ ์ค์์ ๊ฐ์ฅ ๊ฐ๋
์ด ๊ฐ๋จํ ๋ชจ๋ธ์ด๋ค. IBM ์ฐ๊ตฌ์์์ ๊ทผ๋ฌดํ๋ ์ฝ๋(E.F.Codd)๊ฐ 1970๋
์ ์ ์ํ๋ค. ์ด ๋ชจ๋ธ์ ์๋ ์ํ์ ์ธ ์ด๋ก ์ ๊ธฐ๋ฐ์ผ๋ก ํ๋ค. ์ฝ๋๊ฐ ์ํ์์๊ธฐ ๋๋ฌธ์ ์ํ ๋ถ์ผ, ํนํ ์งํฉ๋ก ๊ณผ ๋
ผ๋ฆฌ๋ถ์ผ์ ๊ฐ๋
์ ์ฌ์ฉํ๋ค. ๋ฐ์ดํฐ ๋ชจ๋ธ์ ๊ฐ๋ฐํ๊ธฐ ์ํด์ ํ
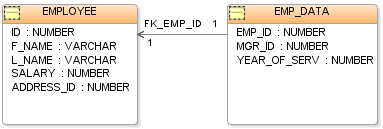
์ด๋ธ ๊ด๊ณ๋ก ๋ฌ์ฌํ๋ ์ด๋ก ์ ๋ชจ๋ธ ๊ณผ์ ์ด ๋ฐ์ํ๋๋ฐ ์ด๋ฅผ ๊ฐ์ฒด๊ด๊ณ๋ชจ๋ธ(์์ด:entity relational model)์ด๋ผ๊ณ ํ๋ค. ์ด ๊ด๊ณ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ฅผ ์ํ ์ค๊ณ๊ณผ์ ์ ์ด๋ก ์ ์ผ๋ก ๊ด๊ณ์ํ์ ๊ธฐ์ดํ ์ค์ง ๊ตฌํ์ด๋ผ ๋ณด๋ฉด ๋๋ค. ํ์ค ์ธ๊ณ๋ ๊ฐ์ฒด๊ด๊ณ ๊ทธ๋ฆผ(๋ค์ด์ด๊ทธ๋จ)์ผ๋ก ํํ๋๋ฉฐ, ๊ฐ์ฒด์ ๊ทธ ๊ด๊ณ๋ ๊ฐ๊ธฐ ์ฌ๊ฐ๊ณผ ์ ์ผ๋ก ๊ทธ๋ ค์ง๋ค.
SQL
๊ฐ์ฒด ๊ด๊ณํ ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ฅผ ์ง์ํ๊ธฐ ์ํด 1974๋
IBM ์ฐ๊ตฌ์์์ ๋ง๋ SQL(Structured Query Language)(์์ด(SEQUEL):Structured English Query Language)๊ฐ ์ฐฝ์๋์์ผ๋ฉฐ, ์ด ์ธ์ด๋ ์ํ์ ๊ด๊ณ ๋์์ ๊ด๊ณ ๋
ผ๋ฆฌ(relational calculus)์ ๊ธฐ๋ฐ์ ๋๊ณ ์๋ค. ๋ฐ์ดํฐ ๋ชจ๋ธ์ ๋ฐ์ดํฐ๋ฅผ ์กฐ์ํ๊ธฐ ์ํ ์ฐ์ฐ์งํฉ์ ๊ฐ์ ธ์ผ ํ๋ค. ์๋ํ๋ฉด ๊ทธ๊ฒ์ ๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ตฌ์กฐ์ ์ ์ฝ ์กฐ๊ฑด์ ์ ์ํ๊ธฐ ๋๋ฌธ์ด๋ค. ๋ค์ ๋งํด, ๊ด๊ณ ๋ฐ์ดํฐ๋ชจ๋ธ ์ฐ์ฐ์งํฉ(a set of operations)์ ๊ด๊ณ๋์๋ก ํํ๋๊ณ , ๊ทธ ์ฐ์ฐ์ ์ฌ์ฉ์์๊ฒ ์ฌ๋ฌ ์ง์๋ฅผ ๊ฐ๋ฅํ๊ฒ ํ๋ค.
๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ด๋ฆฌ ์์คํ
์ ํ
๋ฐ์ดํฐ๋ฒ ์ด์ค ์ค๊ณ ํ ๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ด๋ฆฌ ์์คํ
์ ์ฌ์ฉํด์ผ ํ๋ค. ์ฌ๋ฌ ๊ฐ์ง ๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ด๋ฆฌ ์์คํ
์ ํ ์ฌํญ(DBMS)์ด ์กด์ฌํ๋ค.
๋ฐ์ดํฐ๋ฒ ์ด์ค ๊ด๋ฆฌ ์์คํ
์ผ๋ก ํ์ฌ์๋ ๋ง์ด ์ฌ์ฉํ์ง ์์ผ๋ IBM ๋ฉ์ธํ๋ ์ ํ๊ฒฝ ํ์์ ์ด์๋๋ 'IMS'๊ฐ ์๋ค. IMS๋ ์ ๋ณด ๊ด๋ฆฌ ์์คํ
(Information Management System)์ ์ฝ์๋ก DBMS์ DC ๊ธฐ๋ฅ์ ์ํํ๋ค. IMS๊ฐ ๊ด๋ฆฌํ๋ DB ์ข
๋ฅ์๋ 'DEDB'์ 'MSDB'๊ฐ ์๋ค. DEDB๋ Data Entry DB๋ก ์ ํต์ ์ธ ๊ณ์ธตํ DB์ด๋ฉฐ MSDB๋ ์ฃผ๊ธฐ์ต DB๋ก ์์คํ
๊ฐ๋์ ์ฃผ ๋ฉ๋ชจ๋ฆฌ์ ์์ฃผํ๋ DB๋ก ๋น ๋ฅธ ์ ๊ทผ์ด ํ์ํ ์
๋ฌด์ ์ฌ์ฉ๋๋ค. ๋ค๋ง, ์ ๊ทผ ์๋๊ฐ ๋งค์ฐ ๋น ๋ฅธ ๋ฐ๋ฉด ๋ฉ๋ชจ๋ฆฌ์ ์์ฃผํ๊ธฐ ๋๋ฌธ์ ์ฉ๋ ๋ฐ ๊ตฌ์กฐ์ ์ ํ์ด ๋ง๋ค.
DBMS ์ธ์ด ์ ํ
๋ฐ์ดํฐ๋ฒ ์ด์ค ์ธ์ด๋ ๋ค์๊ณผ ๊ฐ์ด ์ด๋ฃจ์ด์ ธ ์๋ค.
ํธ๋์ญ์
ํธ๋์ญ์
์ ํ๋์ ๋
ผ๋ฆฌ์ ๋จ์๋ฅผ ๊ตฌ์ฑํ๋ ๋ฐ์ดํฐ๋ฒ ์ด์ค ์ฐ์ฐ์ ๋ชจ์์ด๋ค. ๋์์ ์ฌ๋ฌ ํธ๋์ญ์
์ด ์ํ๋๊ธฐ ์ํด์ ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ์ผ๊ด์ฑ์ด ๋ณด์ฅ๋์ด์ผ ํ๋ฉฐ ์ด๋ฅผ ์ํด ๋์์ฑ ์ ์ด(concurrency control)์ ํ๋ณต ์ ์ด(recovery control)๋ฅผ ์ํ ๋ชจ๋์ด ์์ผ๋ฉฐ ์ด ๋์ ํฉ์ณ ํธ๋์ญ์
๊ด๋ฆฌ ๋ชจ๋(transaction management module)์ด๋ผ๊ณ ํ๋ค.
- ๋์์ฑ์ ์ด ๋ชจ๋(concurreny control module): ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ฅผ ์ผ๊ด์ฑ ์๊ฒ ์ ์งํ๊ธฐ ์ํ์ฌ ๋์์ ์ํ๋๋ ํธ๋์ญ์
๋ค ์ฌ์ด์ ์ํธ์์ฉ์ ์ ์ดํ๋ค.
- ํ๋ณต์ ์ด ๋ชจ๋(recovery control module): ๋ฐ์ดํฐ๋ฒ ์ด์ค๋ฅผ ์ผ๊ด์ฑ ์๊ฒ ์ ์งํ๊ธฐ ์ํ์ฌ ์
๋ฐ์ดํธ๋ฅผ ํ๋ ๋์ ์์คํ
์ฅ์ ์๋ ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ๊ธฐ์กด ์ํ๊ฐ ์ ์ง๋๋ค.
ํธ๋์ญ์
์ค์ผ์ค๋ง์ ๋ค์๊ณผ ๊ฐ์ 3๊ฐ์ง ๊ฐ๋
์ ๊ฐ์ง๋ค.
- ์ง๋ ฌ ์ค์ผ์ค๋ง(serial scheduling): ํธ๋์ญ์
์ฐ์ฐ๋ค์ ๊ฐ ํธ๋์ญ์
๋ณ๋ก ์ฐ์์ ์ผ๋ก ์คํํ๋ ๋ฐฉ๋ฒ
- ๋น์ง๋ ฌ ์ค์ผ์ค๋ง(nonserial scheduling): ํธ๋์ญ์
์ฐ์ฐ๋ค์ ์ํธ์ (interleaving)์ผ๋ก ๋ณํ ์คํํ๋ ๋ฐฉ๋ฒ
- ์ง๋ ฌ ๊ฐ๋ฅ ์ค์ผ์ค๋ง(serializable scheduling): ๋น์ง๋ ฌ ์ค์ผ์ค๋ง S๊ฐ ํญ์ ์ง๋ ฌ ์ค์ผ์ค๋ง SS์ ๋ํด์ ๊ฐ์ ๊ฒฐ๊ณผ๋ฅผ ๊ฐ์ง ๋ "S๋ฅผ ์ง๋ ฌ๊ฐ๋ฅ"ํ๋ค๊ณ ํ๋ค.
์ง๋ ฌ๊ฐ๋ฅ ํธ๋์ญ์
์ ๋ณด์ฅํ๊ธฐ ์ํ ๊ท์ฝ(protocol)์ด ์๋๋ฐ ์ ๊ธ(locking) ๋ฐฉ๋ฒ๊ณผ ์๊ฐํ(timestamp)๊ฐ ๋ฐ๋ก ๊ทธ๊ฒ์ด๋ค.
๋ฐ์ดํฐ๋ฒ ์ด์ค ์๋ฃ๊ตฌ์กฐ
์ธ๋ฑ์ฑ
๋ฐ์ดํฐ๋ฒ ์ด์ค๋ ํํ ๋ค์๊ณผ ๊ฐ์ ACID ๊ท์น์ ๋ง์กฑํด์ผ ํ๋ค.
- ์์์ฑ (ๅๅญๆง, Atomicity): ํ ํธ๋์ญ์
์ ๋ชจ๋ ์์
์ด ์ํ๋๋ ์ง, ์๋๋ฉด ํ๋๋ ์ํ๋์ง ์์์ผ ํ๋ค. ํธ๋์ญ์
์ด ์ ๋๋ก ์คํ๋์ง ์์์ผ๋ฉด ๋กค๋ฐฑ(roll back)ํ๋ค.
- ์ผ๊ด์ฑ (ไธ่ฒซๆง, Consistency): ๋ชจ๋ ํธ๋์ญ์
์ ๋ฐ์ดํฐ๋ฒ ์ด์ค์์ ์ ํ ๋ฌด๊ฒฐ์ฑ (็ก็ผบๆง, integrity) ์กฐ๊ฑด์ ๋ง์กฑํด์ผ ํ๋ค.
- ๊ฒฉ๋ฆฌ์ฑ (้้ขๆง, Isolation): ๋ ๊ฐ์ ํธ๋์ญ์
์ด ์๋ก์๊ฒ ์ํฅ์ ๋ฏธ์น ์ ์๋ค. ํธ๋์ญ์
์ด ์คํ๋๋ ๋์์ ๊ฐ์ ๋ค๋ฅธ ํธ๋์ญ์
์ด ์ ๊ทผํ ์ ์์ด์ผ ํ๋ค.
- ๋ด๊ตฌ์ฑ (่ไน
ๆง, Durability): ํธ๋์ญ์
์ด ์ฑ๊ณต์ ์ผ๋ก ๋๋ ๋ค์๋, (์์คํ
์คํจ๊ฐ ์ผ์ด๋๋๋ผ๋) ๊ทธ ๊ฒฐ๊ณผ๊ฐ ๋ฐ์ดํฐ๋ฒ ์ด์ค์ ๊ณ์ ์ ์ง๋์ด์ผ ํ๋ค.
๋ณํ์ ์ด (็ซ่กๅถๅพก, concurrency control)๋ ํธ๋์ญ์
์ ์์ ํ๊ฒ ์ฒ๋ฆฌํ๊ณ ACID ๊ท์น์ ๋ง์กฑ์ํค๋ ๊ธฐ์ ์ด๋ค.
๋ฐ์ดํฐ๋ฒ ์ด์ค์ ์์
| ํ์ฌ ์ด ๋ฌธ๋จ์ ์ฃผ๋ก ๋ํ๋ฏผ๊ตญ์ ํ์ ๋ ๋ด์ฉ๋ง์ ๋ค๋ฃจ๊ณ ์์ต๋๋ค.
๋ค๋ฅธ ๊ตญ๊ฐยท์ง์ญ์ ๋ํ ๋ด์ฉ์ ๋ณด์ถฉํ์ฌ ๋ฌธ์์ ๊ท ํ์ ๋ง์ถ์ด ์ฃผ์ธ์. ๋ด์ฉ์ ๋ํ ์๊ฒฌ์ด ์์ผ์๋ฉด ํ ๋ก ๋ฌธ์์์ ๋๋์ด ์ฃผ์ธ์. (2017๋
12์) |
๋ํ๋ฏผ๊ตญ
2012๋
ํ๊ตญ์ ๊ตญ๋ด DB์ฐ์
์ DB๊ตฌ์ถ ์์ฅ, DB์ปจ์คํ
ยท์๋ฃจ์
์์ฅ, DB์๋น์ค ์์ฅ ๋ฑ ๋ชจ๋ ๋ถ์ผ์์ ์ ๋
๋๋น ๋์ ์ฑ์ฅ์ธ๋ฅผ ๋ํ๋ด๊ณ ์๋ค. ํนํ ์ ์ฐ์
์์์ ์ ๋ณดํต์ ๊ธฐ์ (ICT) ์ตํฉ๊ณผ ์ค๋งํธ ํ๊ฒฝ ํ์ฐ, ๋น
๋ฐ์ดํฐ ๊ด๋ จ ์์๊ฐ ์ฆ๊ฐํ๋ฉด์ ํฅํ ๊ทธ ์ฑ์ฅ์ธ๋ ๊ณ์๋ ๊ฒ์ผ๋ก ๋ด๋ค๋ดค๋ค. ๋ณด๊ณ ์์์๋ DB์ฐ์
์ ์ฑ์ฅ์ ๋ด๋ค๋ณด๋ ์ฃผ์ ์์ธ์ผ๋ก ๋น
๋ฐ์ดํฐ ๋ถ์ยทํ์ฉ์ ์ํ ๊ธฐ์
์ ์ ๊ท ์์ ์ฆ๊ฐ, DB์์ฐ ๊ฐ์น ์ธ์ ์ฆ๋๋ก ์ธํ DB๊ตฌ์ถ ํฌ์ ์ฆ๊ฐ, ์ค๋งํธ ๊ธฐ๋ฐ์ ๋ชจ๋ฐ์ผ ์๋น์ค ํ์ฐ ๋ฑ์ ๊ผฝ๊ณ ์๋ค.[5]
๊ฐ์ด ๋ณด๊ธฐ
๊ฐ์ฃผ
์ฐธ๊ณ ๋ฌธํ
- Elmasri, Navathe:Fundamentals of database systems, Addision Wesley.
์ธ๋ถ ๋งํฌ
|
|---|
| ๊ณตํต ๋ชจ๋ธ | |
|---|
| ๊ธฐํ ๋ชจ๋ธ | |
|---|
| ๊ตฌํ์ฒด | |
|---|
|
|---|
|
| ๊ฐ๋
| |
|---|
| ๊ฐ์ฒด | |
|---|
| SQL | |
|---|
| ๊ตฌ์ฑ์์ | |
|---|
|

.PNG)